


A continuación le presentamos un caso de uso interesante y complicado. Se trata de descubrir rebotar métricas para visitas que se originan en resultados de búsqueda orgánicos de Google. En specific, la métrica que nos interesa es cuánto tiempo el usuario habitado en la página de destino después de llegar desde la búsqueda orgánica de Google Y regresó a la página de resultados del motor de búsqueda (SERP) usando el botón Atrás del navegador.
La inspiración para esta publicación surgió de una pregunta de la audiencia en la Conferencia Greatest Web en Lituania, a la que asistí recientemente como orador. Les preocupaba que Google estuviera utilizando la tasa de rebote como señal de clasificación de búsqueda, y yo tenía la firme opinión de que simplemente no es posible, ya que todas las métricas de GA “nativas” son realmente fáciles de manipular. Sin embargo, el Dr. Pete de Moz escribió sobre tiempo de permanencia en 2012, y tiene mucho sentido. Google debería ser muy Me interesa cuánto tiempo el visitante permanece fuera de la SERP cuando sigue un enlace. Si los usuarios tienden a regresar inmediatamente al SERP, es muy possible que el resultado no fuera relevante para ellos.
Entonces, inspirado por esta pregunta, quería ver si puedo obtener algunas métricas de cuánto tiempo permanecen las personas en estas páginas de destino antes de regresar al SERP. Obtuve mis resultados, pero definitivamente no es un problema fácil de resolver. Como de costumbre, estamos usando una combinación de Administrador de etiquetas de Google y Google Analytics para realizar la operación.
(ACTUALIZACIÓN 17 de abril de 2016 Actualicé este artículo porque tuve que hacer algunas modificaciones en el código. Ahora es un poco más sólido y se adapta mejor, por ejemplo, a métricas personalizadas, si prefiere usarlas en lugar de tiempos de usuario).
El resultado es una lista de tiempos de usuario, donde cada página de destino se puede examinar en comparación con el tiempo que los usuarios pasaron allí antes de hacer clic en el botón Atrás del navegador.
incógnita
El boletín a fuego lento
Suscríbete al Boletín a fuego lento para recibir las últimas noticias y contenido de Simo Ahava en su bandeja de entrada de correo electrónico.
El misterio de la historia.
La dificultad es que cuando el usuario hace clic en el botón Atrás del navegador, no tenemos conocimiento de a dónde se dirige al usuario. Esa es la seguridad del navegador para usted. Sería muy cuestionable si el sitio internet tuviera acceso al historial del navegador internet. Tiene sentido, ¿verdad?
Otra dificultad es el botón Atrás del navegador. No es parte del modelo de objetos del navegador, por lo que en realidad no podemos medir los clics en él. En cambio, podemos inferir ¡Un clic en el botón Atrás de cómo las personas navegan con hashes de URL! cuando un cambio de hash se registra, podemos inferir que se debió al retroceso del navegador si Implementamos un pequeño truco, donde el hash es exclusivo de la búsqueda orgánica de Google.
Verá, al crear una nueva entrada en el historial del navegador para las personas que llegan desde la búsqueda orgánica de Google, el clic en el botón Atrás no los lleva al SERP, sino a la página de destino authentic que existía. antes Redirigimos al usuario al nuevo estado del historial. Usando eso como indicador, podemos extrapolar que el cambio de hash se produjo debido a un clic en el botón Atrás del navegador (o al retroceso).
el proceso
El proceso es el siguiente:
-
Si el usuario llega al sitio a través de una búsqueda orgánica en Google, cree una nueva entrada del historial del navegador con el hachís #gref
-
Más tarde, si un cambio de hash está registrado, y el usuario todavía está en la página de destino, y el cambio de hash es de #gref a una cadena en blanco, lively un Google Analytics momento evento, después de lo cual invoca mediante programación el evento “Atrás” en el historial del navegador
Parece easy (en realidad, no lo parece en absoluto), pero es realmente muy complicado. Verás, estamos manipular el historial del navegador creando una nueva entrada ficticia llamada #gref. Luego, cuando el usuario vuelve a hacer clic en el navegador, en lugar de volver a la búsqueda de Google, en realidad lo lleva al estado anterior, que es la URL. sin el #gref.
ASÍ es como sabemos que el usuario volvió a hacer clic en el navegador Y que estaba intentando regresar al SERP. Todo lo que tenemos que hacer es enviar el hit de tiempo de Google Analytics y luego mover al usuario manualmente a la entrada anterior en el historial (es decir, el SERP).
¿Por qué es hacky? Bueno, estás manipulando el historial del navegador, por ejemplo. Estás creando un estado personalizado y estás obligando al usuario a adoptar ese estado si llega desde la búsqueda orgánica. A continuación, está interceptando un evento de retroceso legítimo del navegador y, en lugar de permitir que el usuario abandone directamente el sitio, lo obliga a enviar primero el hit de sincronización de GA, antes de devolverlo manualmente al SERP.
¡Uf! Muchas cosas que pueden salir mal. Afortunadamente, JavaScript es sólido y hermoso, ¡pero no olvides probarlo minuciosamente!
Espera, déjame repetir eso: prueba a fondo. Además, si tiene un sitio internet de una sola página, casi puedo prometerle que esto no funcionará de inmediato.
La etiqueta HTML personalizada
En el centro de esta solución se encuentra una única etiqueta HTML personalizada. Está provocado por dos eventos diferentes, a los que volveremos en breve.
Primero que nada, aquí está el código:
Repasemos rápidamente este código. En primer lugar, todo el bloque está encerrado en una expresión de función invocada inmediatamente (IIFE) (perform() {...})();que protege el espacio de nombres international. Además, toda la solución solo funciona si el navegador del usuario admite la API Historial: if (window.historical past) {...}.
El primer bloque de código importante es este:
if (e === 'gtm.js' &&
doc.referrer.indexOf('www.google.') > -1 &&
s.indexOf('gclid') === -1 &&
s.indexOf('utm_') === -1 &&
h !== '#gref') {
window.oldFragment = false;
window.historical past.pushState(null,null,'#gref');
}
Este código verifica lo siguiente:
-
¿Se activó la etiqueta debido al activador de vista de página (es decir, una carga de página)?
-
¿El usuario llegó desde un sitio de Google (
referrercontiene www.google.)? -
Si lo hicieron, asegúrese de que no sea de un anuncio de AdWords (compruebe que la URL no tenga ?gclid) o campaña personalizada.
-
Asegúrese también de que la URL no contenga #gref, lo que implicaría que el usuario siguió un enlace con ese hash o que el usuario ya tenía una entrada en el historial con #gref, lo que significa que navegó a otro lugar dentro o fuera del sitio después aterrizando en él en primer lugar desde el SERP.
Si estas comprobaciones pasan, entonces una nueva variable international oldFragment se inicializa con el valor false. Esto significa simplemente que se trata de un nuevo aterrizaje en el sitio a través de una búsqueda orgánica en Google, y lo comprobamos cuando enviamos la carga útil a dataLayer. Solo queremos enviar el hit de sincronización para los rebotes en la página de destino.
Finalmente, se crea un nuevo estado del historial del navegador, donde a la URL se le añade #gref para mostrar que el usuario llegó desde la búsqueda orgánica de Google.
El siguiente bloque de código es:
else if (e === 'gtm.js') {
window.oldFragment = true;
}
Aquí, verificamos si el evento es una carga de página nuevamente, pero la URL ya tiene #gref. En este caso, configuramos la variable international en trueya que obviamente esta entrada no es un aterrizaje directo desde la SERP sino algo más. De esta manera, bloquearemos el impacto del tiempo, ya que solo queremos medir los rebotes reales de la página de destino.
El bloque de código closing es:
if (e === 'gtm.historyChange' &&
n === '' &&
o === 'gref') {
var time = new Date().getTime() - {{DLV - gtm.begin}};
if (!window.oldFragment) {
dataLayer.push({
'occasion' : 'returnToSerp',
'timeToSerp' : time,
'eventCallback' : perform() {
window.historical past.go(-1);
}
});
} else {
window.historical past.go(-1);
}
}
Nuevamente, hay una lista de verificación de cosas:
-
¿Es el evento un evento del historial del navegador?
-
¿Es el viejo hachís? #gref ¿Y el nuevo hash es una cadena en blanco?
Si todas estas comprobaciones pasan, significa que el usuario intentó volver al SERP en el historial del navegador. Debido a nuestro estado de historial impuesto manualmente, en realidad son llevados al #gref-menos página de destino.
A continuación, verificamos el tiempo de permanencia en la página, utilizando la diferencia entre la hora precise y la hora en que se cargó por primera vez el fragmento del contenedor GTM. Esta es una descripción razonable del tiempo de permanencia, pero puede usar otra cosa para el tiempo de inicio si lo desea.
Finalmente comprobamos si oldFragment es falso, lo que significa que todavía estamos en la página de destino. Si es así, la carga útil se empuja hacia dataLayer. La clave ‘eventCallback’ tiene el retorno actual al comando SERP, y solo se ejecutará después de cualquier etiqueta que use el regresar a Serp evento se ha disparado.
¡Hacky-dy-hack-hack! ¡Me encanta!
Todas las demás cosas que necesitarás
Aquí hay una lista de los activos que necesita crear para que esto funcione. ¡Siéntete libre de improvisar, si lo deseas!
1. Variables integradas
Primero, asegúrese de que las siguientes variables integradas estén marcadas en la configuración de variables de su contenedor.
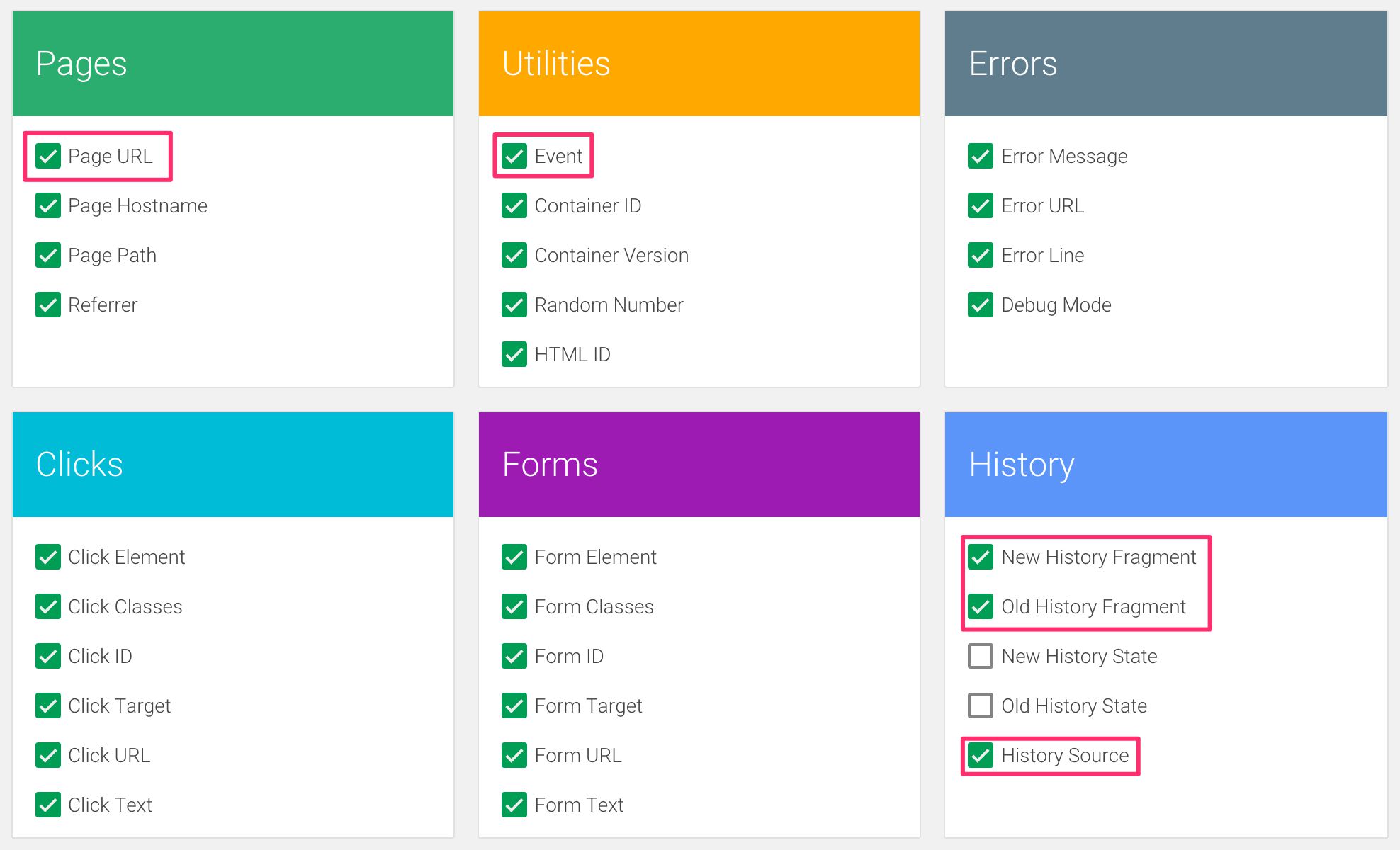
Así que eso es URL de la página, Evento, Fuente histórica, Fragmento de historia nueva/vieja.
2. Los desencadenantes de la etiqueta HTML personalizada
La etiqueta HTML personalizada se ejecuta en dos activadores.
El primero es el predeterminado. Todas las páginas Desencadenar.
El segundo es un Cambio de historia Activador que se parece a este:
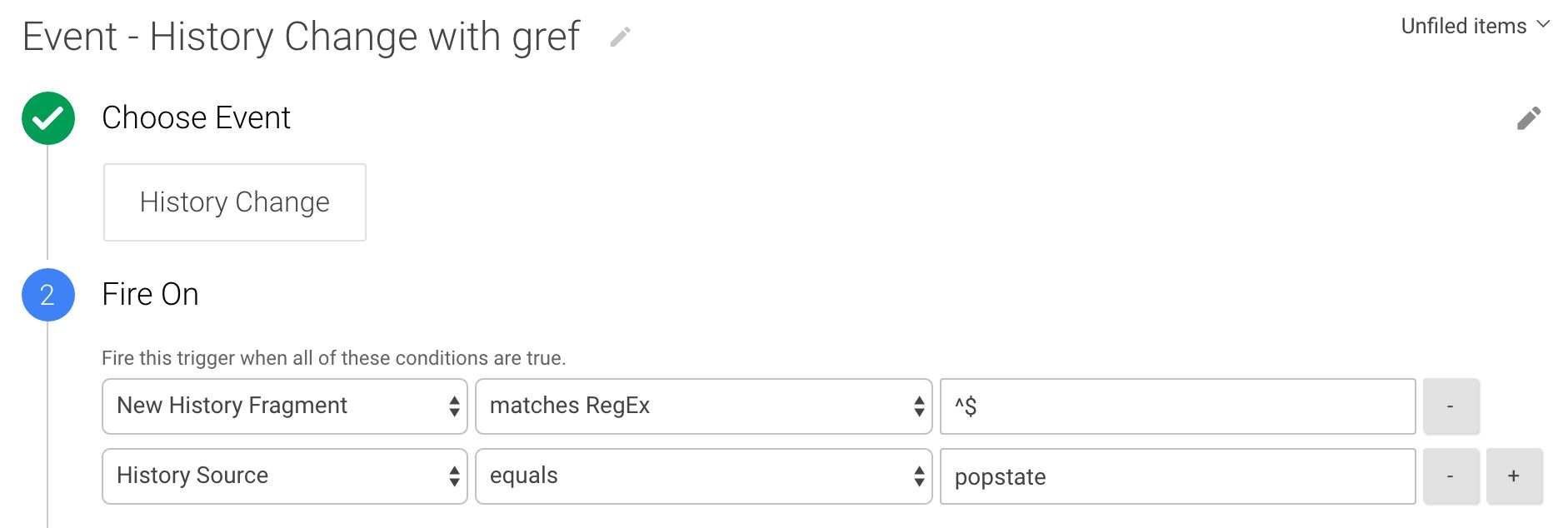
Este activador solo se inicia cuando se detecta un evento en el historial del navegador, que también es un popstatey el nuevo fragmento del historial está vacío.
3. Las variables
Cree las siguientes variables de capa de datos:
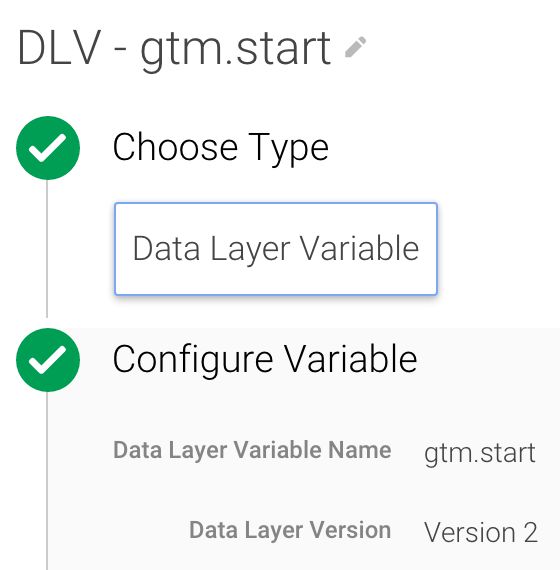
Éste almacena la hora en que se ejecutó el fragmento del contenedor GTM.
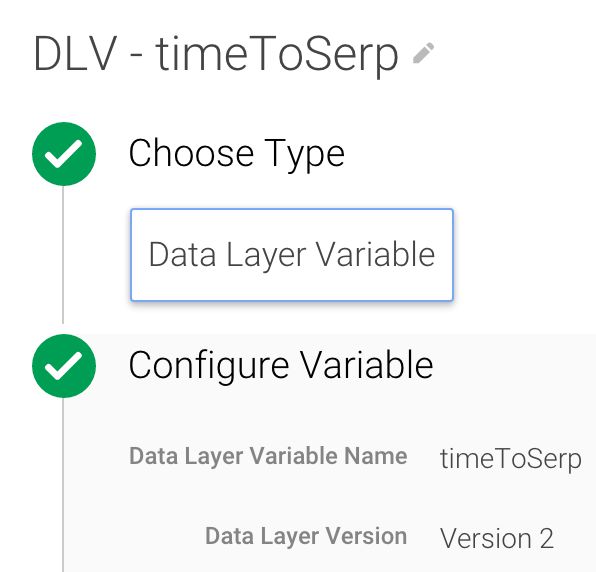
Aquí es donde se almacena el tiempo pasado en la página de destino.
4. El desencadenante de la etiqueta de sincronización
El activador que adjuntará a la etiqueta de sincronización (que se crea a continuación) se ve así:
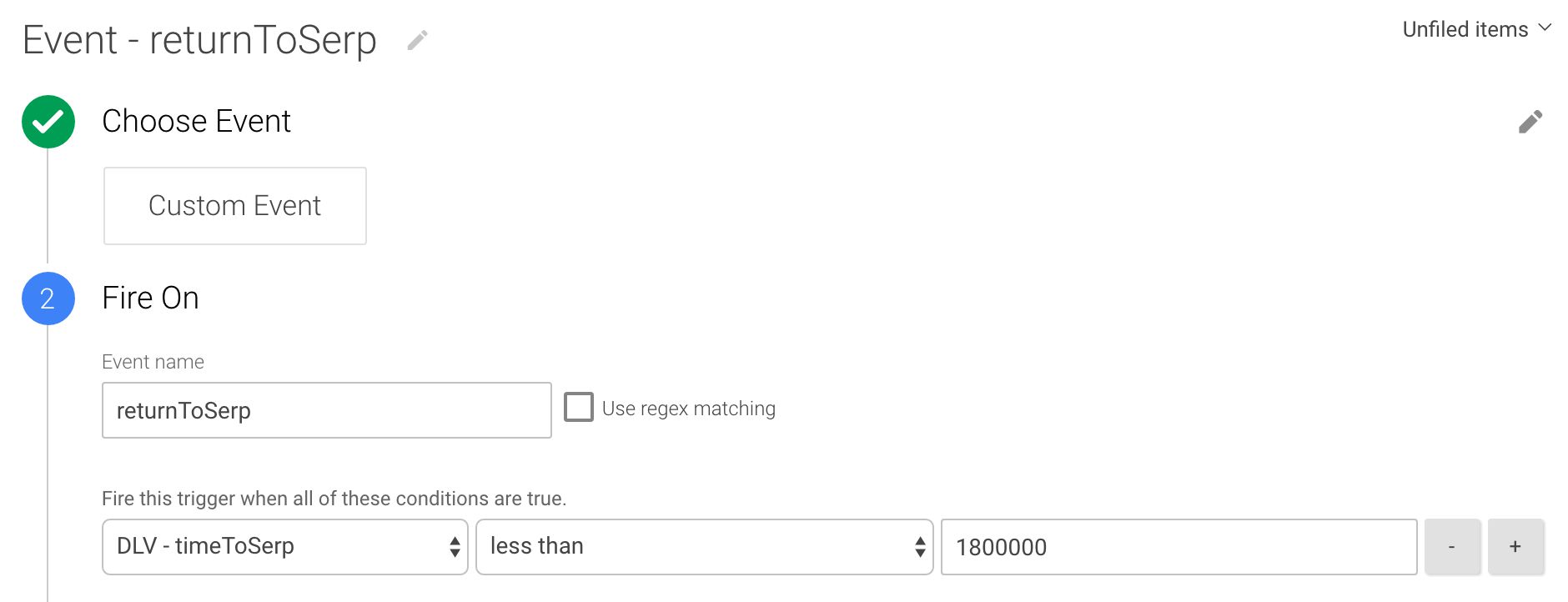
Este disparador se activa cuando el regresar a Serp dataLayer El evento se envía a través de la etiqueta HTML personalizada. También comprueba que el tiempo de permanencia introducido en dataLayer es menos de 30 minutos. De esta manera no se iniciará una nueva sesión con el evento si el visitante permanece en la página durante un tiempo excepcionalmente largo.
5. La etiqueta de tiempo
Y aquí está la etiqueta de sincronización de Common Analytics que necesitará:
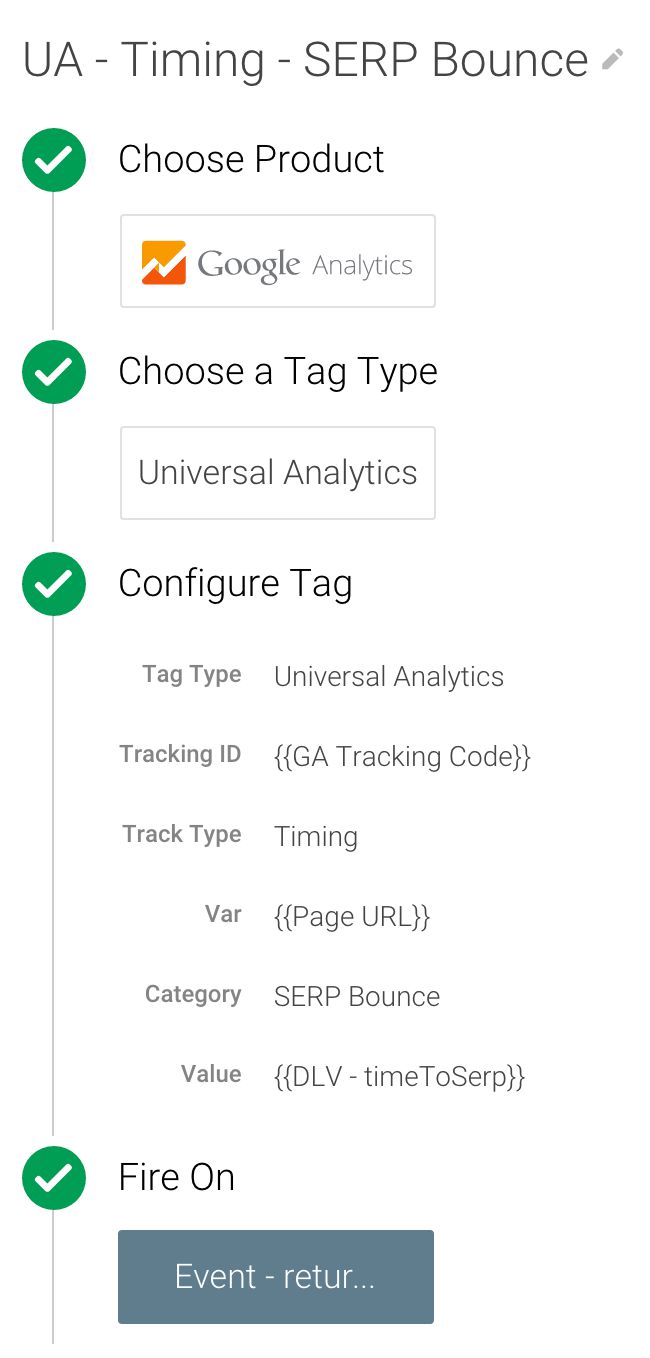
estamos enviando Rebote SERP como categoría de cronometraje, el whole URL de la página como la variable de tiempo, y el tiempo invertido en la página de destino como valor. Como se mencionó anteriormente, esta etiqueta es activada por el disparador que creó en el paso (4) anterior.
Ver los resultados
Una vez que implemente esto, encontrará los resultados en Contenido del sitio > Velocidad del sitio > Tiempos de usuario bajo la categoría de sincronización etiquetada Rebote SERP.
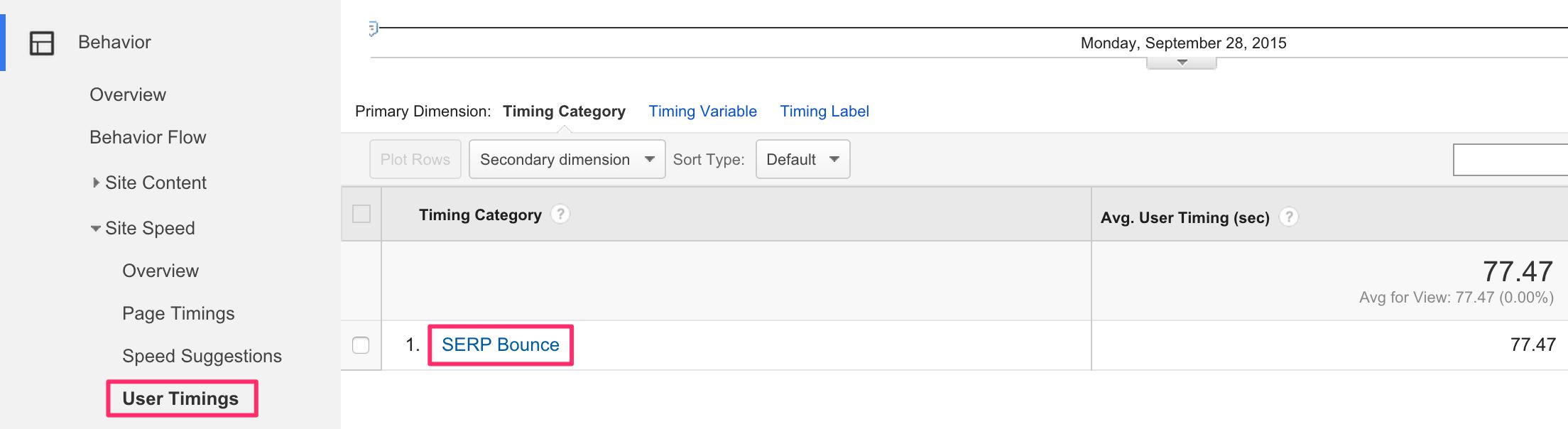
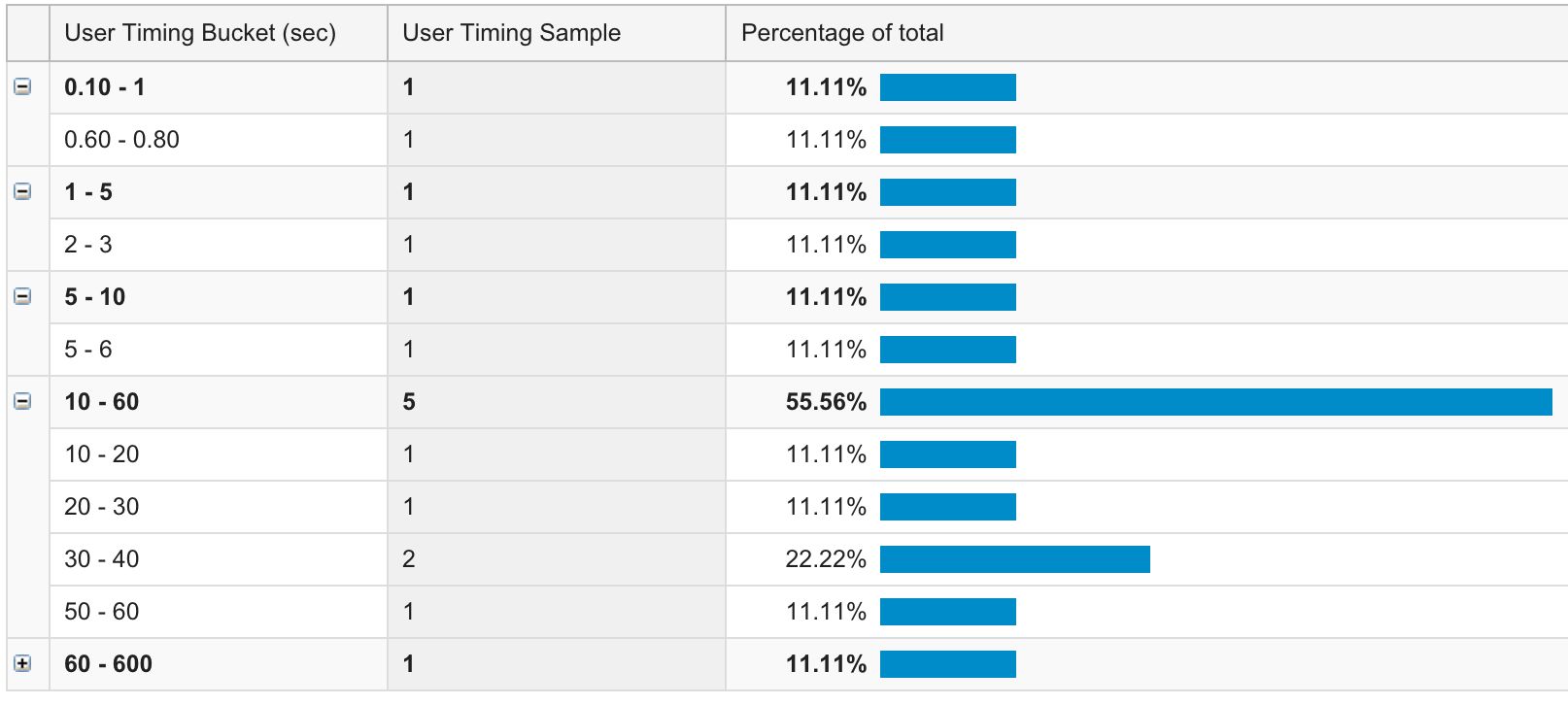
Para profundizar en los datos, es útil ver la variable de tiempo como la dimensión principal, ya que es allí donde se encuentran las páginas de destino. Intente encontrar páginas de destino con un tiempo de permanencia promedio anormalmente pequeño:
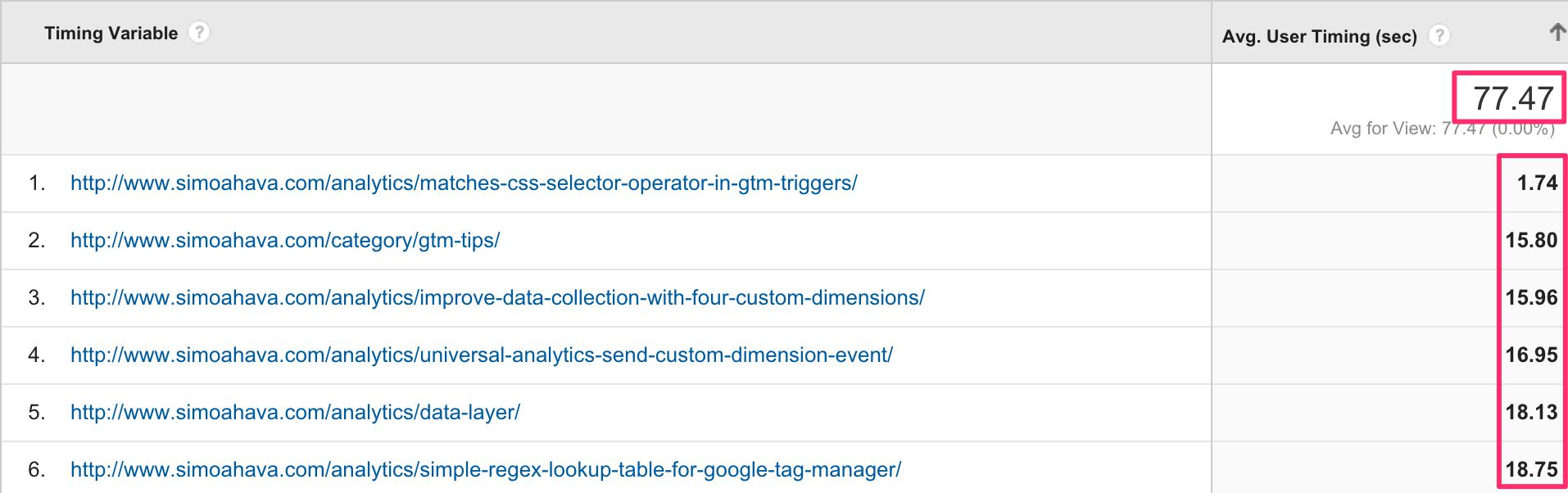
Estas páginas tienen un tiempo de permanencia muy corto en comparación con el promedio del sitio. Sólo asegúrese de que el muestra de tiempo es lo suficientemente grande como para que usted pueda sacar conclusiones. Páginas con un tiempo de permanencia anormalmente corto en SERP PODRÍA indicar una mala experiencia o falta de contenido relevante.
Además, el Distribución La vista es útil si desea profundizar en el rendimiento de una página particular person:
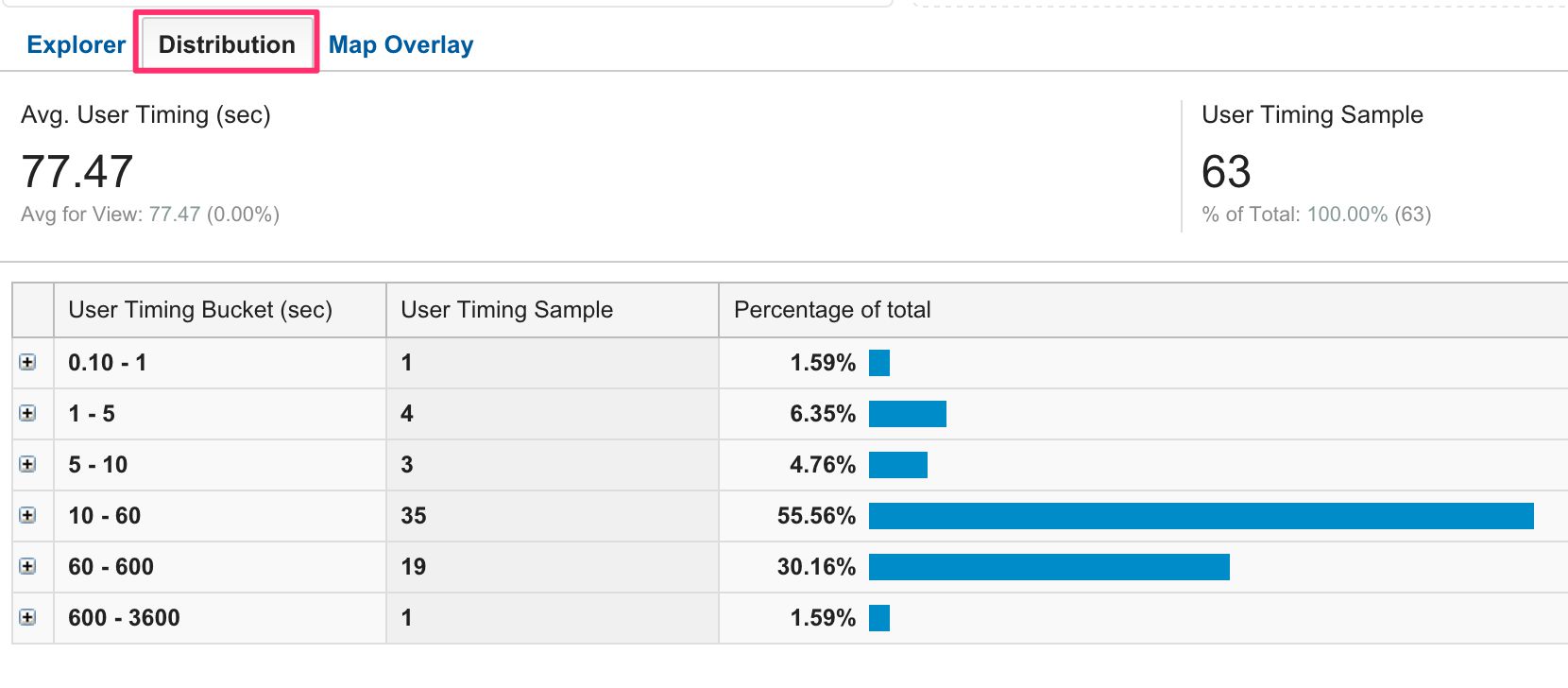
Este informe le permite ver los intervalos de tiempo. Como puede ver, aquí hay algunas anomalías, aunque la muestra es bastante pequeña.
Resumen
Espero haberte convencido ya de que esta es una solución muy complicada. Recuerde probar minuciosamente. También puedo prometerle que tendrá problemas si intenta implementar esto en una aplicación de una sola página (por ejemplo, un sitio AJAX), que depende de la API del historial del navegador para la navegación.
Sin embargo, es una forma interesante de descubrir posibles problemas con sus páginas de destino. Sería interesante alinear estos datos con los datos de palabras clave, pero eso depende de usted resolverlo, ya que esos datos son difíciles de conseguir hoy en día y los tiempos de usuario no se alinean bien con dimensiones de adquisición como palabras clave.