


Administrador de etiquetas de Google‘s Capa de datos es algo que he mencionado en casi todos mis artículos. Es una parte integral de lo que hace que una solución de administración de etiquetas sea excelente y aplicable a una variedad de escenarios comerciales. También hablé extensamente sobre el modelo de datos internos de Google Tag Supervisor, y esto #GMTConsejos La publicación está muy relacionada con este concepto bastante turbio.
En esta publicación, repasaremos el Versión variable de capa de datos selección, e intentaré explicar qué hace este selector.
incógnita
El boletín a fuego lento
Suscríbete al Boletín a fuego lento para recibir las últimas noticias y contenido de Simo Ahava en su bandeja de entrada de correo electrónico.
Consejo 40: Las dos caras de la variable de capa de datos
Empecemos por dar un paso atrás. Como construcción técnica, la “capa de datos” en GTM es una Matriz de JavaScriptque normalmente comprende una serie de objetos simples que han sido metidos en sus entrañas en una página internet.

Como has aprendido de mi artículo sobre modelo de datosGTM en realidad no accede a esta matriz cuando crea sus variables de capa de datos. En cambio, cuando se empuja un objeto hacia dataLayerestá disponible para el modelo de datos de Google Tag Supervisor y cualquier variable de capa de datos que cree hará referencia a estas instancias en el modelo de datos en lugar de acceder directamente a la matriz.
¿Por qué? Desacoplar el Array de los mecanismos internos de la plataforma conectada (GTM en este caso). Esto es bastante importante, ya que cuanto menos GTM necesite depender de la estructura abstracta de dataLayerque podría ser manipulado en cualquier momento mediante un código descuidado u otra plataforma conectada, mejor.
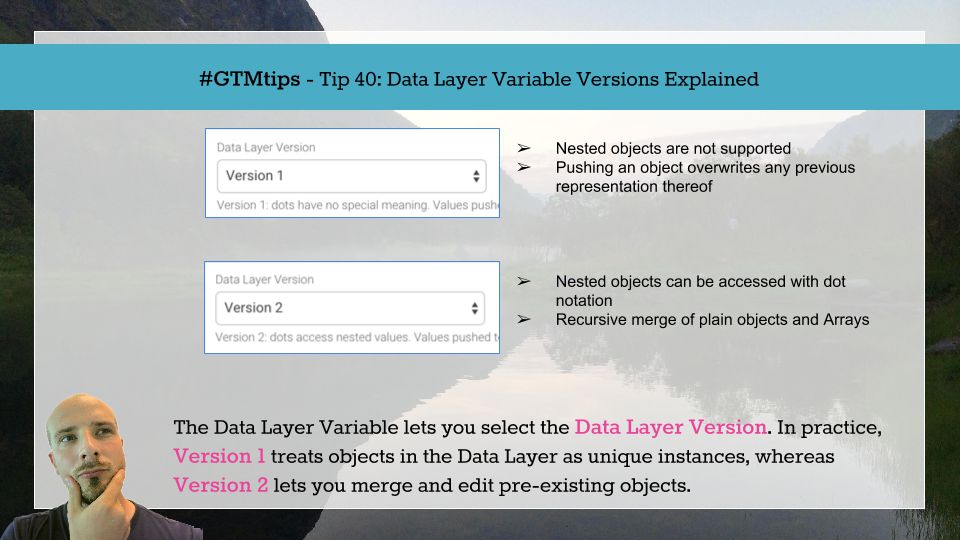
Ahora, cuando seleccionas el Versión de la variable de capa de datos, le está indicando a GTM que trate los valores en el modelo de datos de dos maneras diferentes.
Versión 1
La versión 1 de la variable de capa de datos tiene un alcance muy limitado. Básicamente, el par clave-valor que se introduce en dataLayer debe estar en la raíz del objeto, ya que la Versión 1 no le permite acceder a claves anidadas.
A continuación se muestra un ejemplo de lo que sucedería con una variable de capa de datos de la versión 1 que apunta al nombre de la clave. 'product.worth':
// Works as a result of the dots are in the important thing identify, and the secret's within the root:
window.dataLayer.push({
'product.worth' : '11.99'
});
// Will not work as a result of 'worth' is nested within the 'product' object:
window.dataLayer.push({
'product' : {
'worth' : '11.99'
}
});
Sin embargo, podría acceder al objeto anidado indirectamente con una variable de capa de datos de la versión 1 creando la variable para la clave. 'product'y luego manipular el objeto devuelto en una etiqueta HTML personalizada o una variable JavaScript personalizada.
Y… sí. Eso es todo lo que hace la Versión 1. No hay fusión, ni funciones especiales del modelo de datos, ni nada que pueda usar para manipular aún más el objeto recuperado. Entonces, echemos un vistazo a lo que sucede cuando presiono dos valores diferentes para la misma clave ('product'):
window.dataLayer.push({
'product' : {
'worth' : '11.99'
}
});
window.dataLayer.push({
'product' : {
'identify' : 'Tim Duncan Fan Membership Membership'
}
});
En el ejemplo anterior, si tuviera mi variable de capa de datos de la versión 1 apuntando a 'product'devolvería un objeto easy con {'worth' : '11.99'} después del primer empujón, y un objeto easy con {'identify' : 'Tim Duncan Fan Membership Membership'} después del segundo.
En esencia, cualquier información en el primer impulso está completamente sobrescrito (para esta variable de capa de datos en explicit) mediante la segunda pulsación con el mismo nombre de clave ('product').
Versión 2
Si desea más flexibilidad, utilice la versión 2 de la variable de capa de datos. Esto trata los objetos de forma más parecida a lo que cabría esperar si está familiarizado con el funcionamiento de JavaScript.
En lugar de arrasar con las claves existentes, la Versión 2 primero verifica si ya existe una clave con ese nombre en el modelo de datos. Si es así, fusiona recursivamente información en el nuevo envío con información en el objeto existente.
Veamos un ejemplo:
window.dataLayer.push({
'product' : {
'worth' : '119.99',
'class' : 'Membership'
}
});
window.dataLayer.push({
'product' : {
'worth' : '1199.99',
'identify' : 'Tim Duncan Fan Membership Membership'
}
});
Entonces, digamos que estás usando la versión 2 de la variable de capa de datos y estás apuntando una vez más a la clave con nombre 'product'.
Después del primero dataLayer.push()la variable devolvería un objeto easy con:
{
'worth' : '119.99',
'class' : 'Membership'
}
Después del segundo empujón, el contenido sería:
{
'worth' : '1199.99',
'class' : 'Membership',
'identify' : 'Tim Duncan Fan Membership Membership'
}
¿Puedes ver lo que pasó aquí? Otro objeto con el mismo nombre clave ('product') es empujado. La versión 2 de la variable de capa de datos encuentra una instancia de esta clave dentro del modelo de datos. Luego, verifica recursivamente cada clave dentro de este objeto para ver si hay conflictos.
Primero, encuentra que 'worth' está en ambos objetos, por lo que hay un choque. A continuación, comprueba si 'worth' También es un objeto easy o una matriz para ver si debe realizar otra fusión más profunda en la estructura. Sin embargo, el valor de 'worth' es una cadena, lo que significa que no se realiza ninguna combinación recursiva y el nuevo valor sobrescribe el anterior.
A continuación ve que 'class' no tiene ningún conflicto, por lo que lo deja en el objeto. Finalmente, encuentra una clave completamente nueva en el segundo empujón, 'identify'y fusiona esta clave con el objeto existente en el modelo de datos.
Entonces, al utilizar la versión 2 de la variable de capa de datos, la resolución de conflictos en los nombres de claves de objetos se intenta primero mediante una combinación de los dos objetos, pero si hay nuevos valores “primitivos” para cualquier clave preexistente, sus valores se sobrescriben de la misma manera. estarían con la Versión 1 de la Variable de capa de datos.
¿Así que lo que?
Esta información podría llevar a varias conclusiones, pero supongo que a muchos les vienen a la mente las siguientes dos preguntas:
-
¿Por qué todavía existe la Versión 1? Su easy numeración significaría que es inferior.
-
¿Para qué necesito una fusión recursiva?
Uno de los mejores casos de uso para la Versión 1 es con Comercio electrónico mejorado. Si estás usando el Variable de JavaScript personalizada método, que parece que uso casi exclusivamente, probablemente quieras usar la versión 1 de la capa de datos al interactuar con el 'ecommerce' llave. De esta manera, GTM sólo accederá a la empujón más reciente en dataLayer. ¿Y por qué es esto significativo? Eche un vistazo al siguiente ejemplo:
window.dataLayer.push({
'ecommerce' : {
'impressions' : ({ ... impressions ... })
}
});
// Afterward the identical web page
window.dataLayer.push({
'ecommerce' : {
'element' : { ... product element view ... }
}
});
// And but in a while the identical web page
window.dataLayer.push({
'ecommerce' : {
'add' : { ... add to cart motion ... }
}
});
si usaste Versión 2 de la variable de capa de datos para enviar la carga útil de comercio electrónico mejorado utilizando el método de variable JavaScript personalizada, terminará con tres Cargas útiles de impresiones, dos Vistas de detalles del producto, y uno Acción Añadir al carrito. Esto se debe a la fusión recursiva del 'ecommerce' ¡objeto! Supongo que su intención es enviar cada carga útil solo una vez.
Entonces, si en su lugar usas Versión 1 de la variable de capa de datos para acceder a la 'ecommerce' objeto, GTM solo accederá a la carga útil que se envió más recientemente a dataLayer. De esta manera terminarás evitando el problema de multiplicación de la carga útil.
En cuanto al segundo punto de para qué sirve la fusión recursiva, hay todo un universo de posibilidades cuando se trata de fusionar objetos en lugar de sobrescribir instancias anteriores. Los ejemplos incluyen:
-
Actualizar un objeto a medida que se revela más información, por ejemplo, recopilar un historial de interacciones en una sola página.
-
Actualizar un objeto a medida que hay más información disponible, por ejemplo, actualizar un objeto de “usuario” cuando se completan ciertas llamadas API.
-
Realizar una combinación válida de dos cargas útiles de comercio electrónico mejorado, como combinar
'impressions'con un'add'objeto.
Hay muchas otras cosas que puedes hacer con la versión 2 de la variable de capa de datos, y todas ellas se detallan en mi artículo sobre modelo de datos.
Espero que esto haya sido esclarecedor y espero que le ayude a comprender la razón por la que ambas versiones están disponibles para la variable de capa de datos.