


Mientras Motor de aplicaciones de Googleel patrón de implementación predeterminado de Administrador de etiquetas de Google del lado del servidores fácil de configurar con el pasos de aprovisionamiento automáticociertamente no es la única forma de implementar el servidor.
De hecho, el guía de configuración handbook le brinda los detalles sobre cómo implementar un servidor de Google Tag Supervisor en cualquier entorno que ejecuta Docker.
Docker es una forma de empaquetar una aplicación completa (como el servidor GTM) en un envaseque luego se puede implementar fácilmente con las herramientas que ofrecen la mayoría de las plataformas de servidores. Leer más aquí.
En esta guía, me basaré en lo que Mark (brillantemente) escribió al desarrollar un Ejecutar en la nube instalación. Para facilitar las cosas, hay una sencilla instalar script puede utilizar para automatizar la mayor parte del proceso.
X
El boletín a fuego lento
Suscríbete al Boletín a fuego lento para recibir las últimas noticias y contenido de Simo Ahava en su bandeja de entrada de correo electrónico.
Consejo #130: Cómo implementar un servidor GTM usando Cloud Run

Cloud Run todavía está equitativamente tecnología reciente, ya que entró en disponibilidad basic a fines de 2019. Si Cloud Run tuviera el conjunto de funciones que tiene hoy, es possible que se hubiera elegido como la integración nativa en Google Tag Supervisor en lugar de App Engine.
Aquí hay un Motor de aplicaciones vs. Ejecutar en la nube tabla que he compilado:
| Motor de aplicaciones | Ejecutar en la nube |
|---|---|
| Se ejecuta en Motor de Computación instancias. | Se ejecuta en contenedores sin servidor. |
| Sin escala a cero (App Engine Versatile). | Se puede configurar para que solo se ejecute cuando se atiendan solicitudes. |
| Comprime archivos automáticamente. | Sin compresión automática. |
| Agrega algunos metadatos adicionales a las solicitudes HTTP. | No modifica las solicitudes HTTP. |
| (Probablemente) más eficiente para una gran cantidad de solicitudes (>100 millones/mes). | (Probablemente) más eficiente para un número menor de solicitudes (<100 millones/mes). |
| Región única, difícil de equilibrar la carga. | Se puede configurar con una purple multirregional mediante un equilibrador de carga. |
| Tecnología establecida. | Tecnología prometedora. |
Como puede ver, la decisión sobre qué tecnología elegir no es fácil. Si estás ejecutando un un gran número de solicitudesparece que App Engine aún podría tener la ventaja, especialmente cuando usas escalado automático y comenzar con un número mínimo apropiado de instancias.
Pero si está procesando una carga de solicitudes más modesta y no necesita específicamente una compresión lista para usar, es posible que disfrute de lo que Cloud Run aporta a la mezcla.
Evidencia anecdótica
Las anécdotas rara vez son útiles, pero las compartiré de todos modos. Después de cambiar de App Engine (3 instanciasatendiendo a ~5 millones de solicitudes por mes) a Cloud Run, esto es lo que encontré.
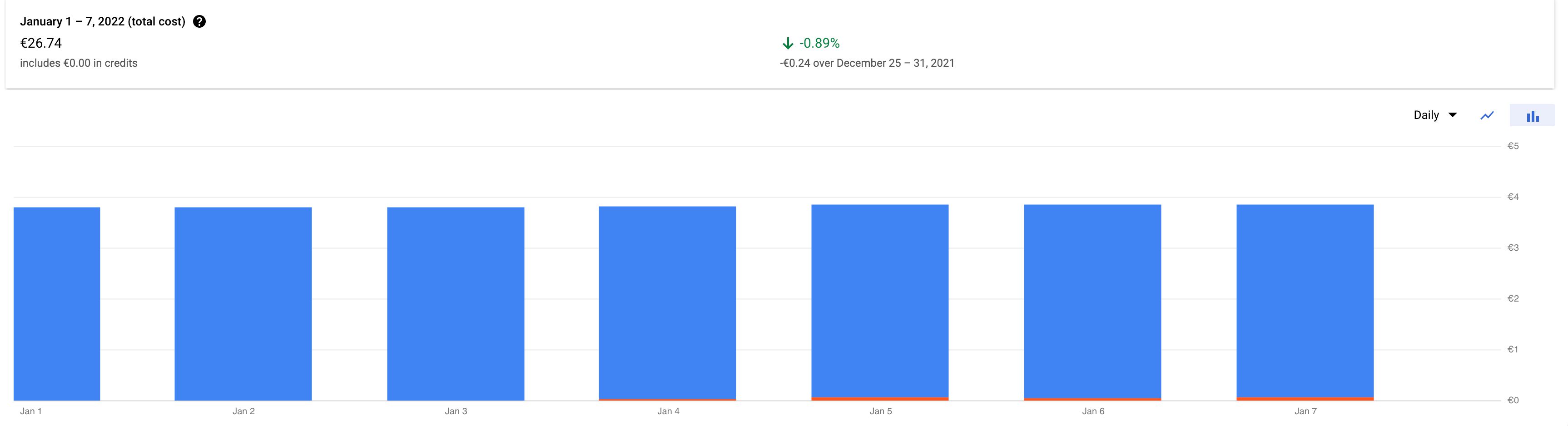
El costo diario de ejecutar tres instancias del motor de aplicaciones (arriba) es un poco menos 4 euros por día. Este es el configuración recomendada de Google Tag Supervisor del lado del servidor.
Sí, podría haber reducido trivialmente a dos o incluso solo una instancia para ahorrar gastos, pero los picos de tráfico pueden ocurrir sin previo aviso, y el tiempo de arranque en frío de una instancia de App Engine puede ser insoportablemente largo.
App Engine también puede ejecutarse agotamiento de recursos problemas dependiendo de la región, donde ni siquiera se puede cumplir con el número mínimo de instancias.
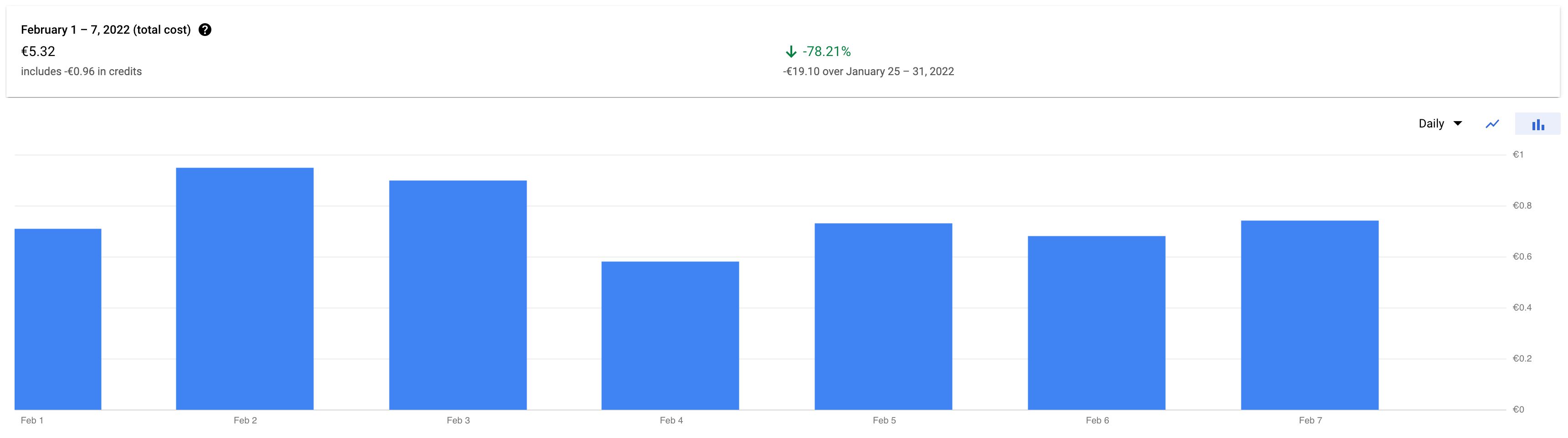
Con Cloud Run bajo demanda, el costo varía de un día a otro, pero en una semana promedio estoy pagando menos de 1 euro por díapor lo que incluso menos de lo que pagaría por un Configuración de App Engine de instancia única (lo que sería arriesgado en caso de picos de tráfico y el largo tiempo de arranque en frío de las instancias de App Engine).
En cuanto a la latencia, esto es lo que muestra Cloud Run:
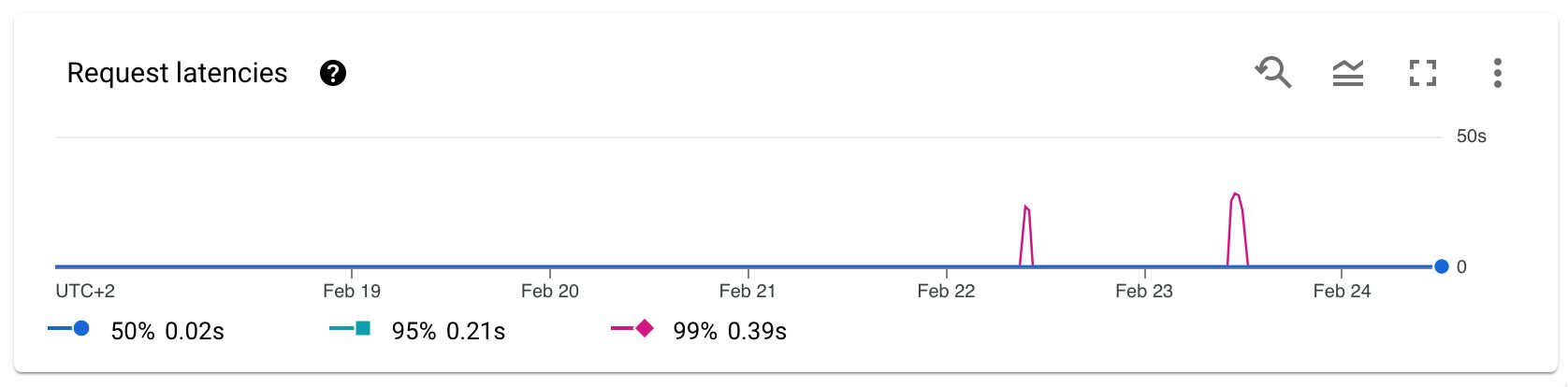
Los valores correspondientes para App Engine fueron (tomado de una muestra arbitraria de 5 días):
- percentil 50: 0,44s
- percentil 95: 0,87s
- percentil 99: 1,13s
No estoy seguro de por qué Cloud Run tiene mejor latencia, considerándolo no comprime archivos automáticamenteentonces gtm.js (Administrador de etiquetas de Google) y gtag.js (World Web site Tag), por ejemplo, se envían completamente sin comprimir a través de la purple.
Por supuesto, estoy contento con estos resultados, pero necesitaré más datos antes de poder sacar más conclusiones.
Y, nuevamente, el sitio en cuestión tiene un tráfico muy modesto (alrededor de cinco millones de solicitudes por mes). Sería interesante ver datos comparativos de diferentes cohortes: decenas de millones de solicitudes mensuales, cientos de millones de solicitudes mensuales, miles de millones de solicitudes mensuales…
Cómo implementar Cloud Run
Si quieres probar Cloud Run, es muy fácil hacerlo. Tu necesitas un Proyecto de nube de Google donde se ha habilitado la facturación.
En el proyecto, enciende Concha de nube haciendo clic en el icono correspondiente en la barra de navegación.
Una vez que se haya iniciado la instancia de Shell, ejecute el siguiente comando:
bash -c "$(curl -fsSL https://uncooked.githubusercontent.com/sahava/sgtm-cloud-run-shell/principal/cr-script.sh)"Esto ejecuta un script de shell que he escrito que le guiará por los pasos de implementación.
- Nombre del Servicio – así se llamará el servicio Cloud Run, con sufijos
-debugpara el servicio de depuración y-prodpara el servicio de etiquetado agregado automáticamente por el script. Elige lo que quieras o usa el recomendado.gtm-serverpresionando enter. - Obtener la configuración del servicio existente – Si ya implementó un servicio Cloud Run, puede usarlo para obtener los detalles de configuración existentes de la región que seleccionará a continuación. Esto es útil ya que completa previamente todas las configuraciones posteriores en el script de shell. Puede omitir este paso presionando Enter.
- Configuración de contenedor – copiar y pegar el cadena de configuración del contenedor desde la interfaz de usuario del contenedor del servidor Google Tag Supervisor haciendo clic en el ID del contenedor en la barra superior.
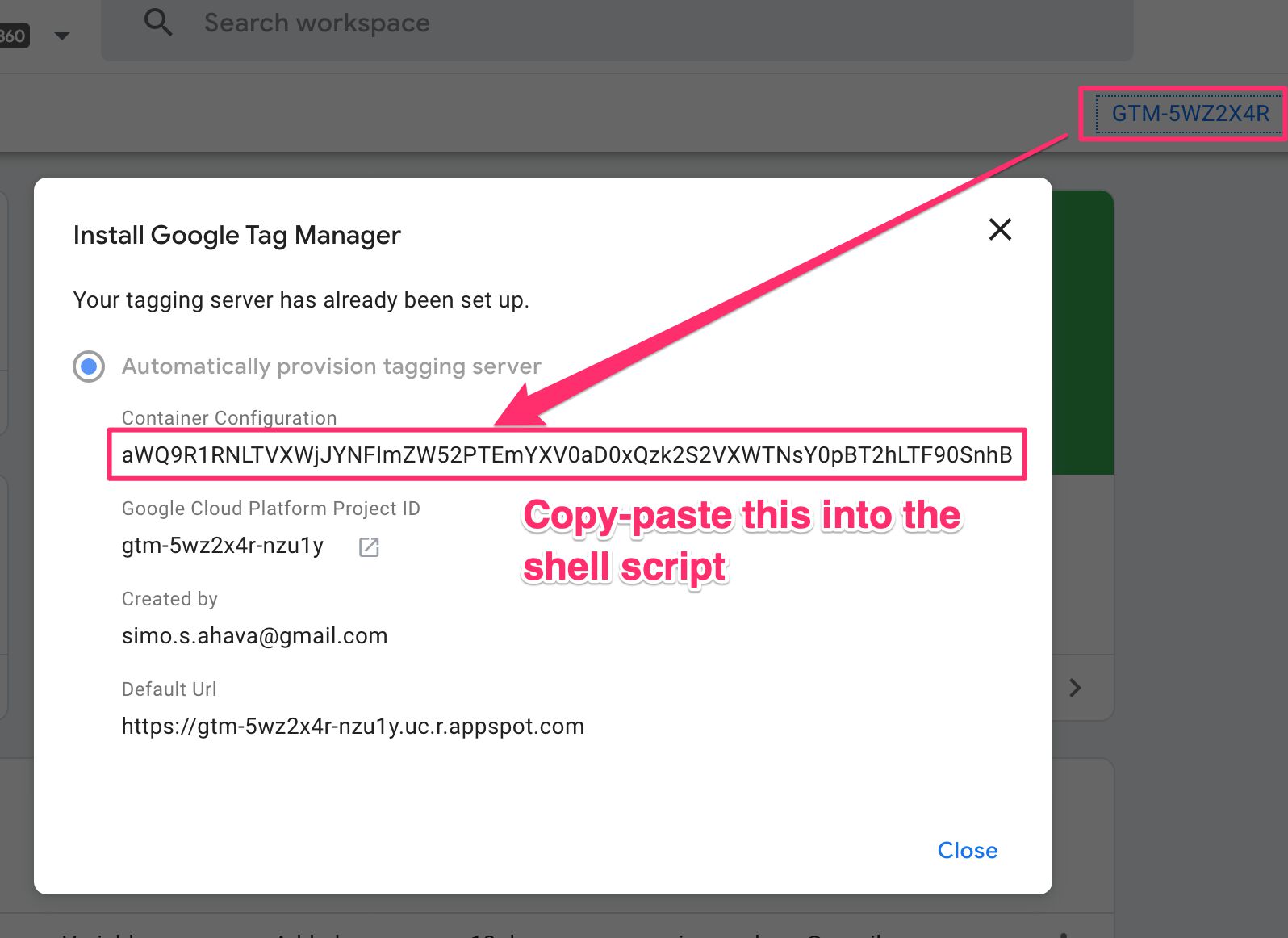
- URL del script de política – si quieres usar un guión de política Para controlar lo que puede hacer un contenedor de servidor, puede agregar la URL al script aquí.
- Memoria por instancia – elija cuánta memoria se reserva por instancia de Cloud Run. Utilice el recomendado 512Mi para reflejar lo que usaría una implementación de App Engine.
- Asignación de CPU por instancia – elija cuántas CPU se asignan por instancia.
- Número mínimo de servidores – Elija a cuántas instancias desea ampliar de forma predeterminada.
- Número máximo de instancias – elija el límite de cuántas instancias puede escalar la implementación.
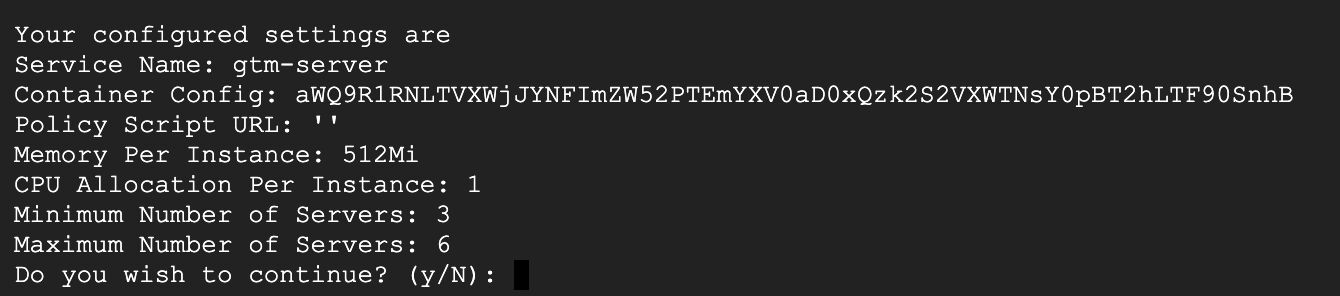
Cuando haya terminado, esto es lo que debería ver. Si está satisfecho con la configuración, simplemente escriba y y presione enter para continuar.
Si aún no ha habilitado la API de Cloud Run, en este punto el script lo hará por usted.
Cada contenedor de servidor se ejecuta en dos servicios: un servicio de depuración y un servicio de etiquetado (llamado servicio de producción en el guión). El servicio de depuración se utiliza únicamente para el modo Vista previa y se ejecuta con una capacidad muy limitada. El servicio de etiquetado es el que configuró en los pasos anteriores.
Implementar el servicio de depuración
Lo primero que tendrás que elegir es el región para el servicio de depuración.
Debes elegir una región geográficamente más cercana a las personas que realizarán la depuración.. Como soy de Finlandia, elegiré el europe-north1 región para el servicio de depuración.
Una vez que haya elegido la región, el servicio tardará un momento en implementarse.
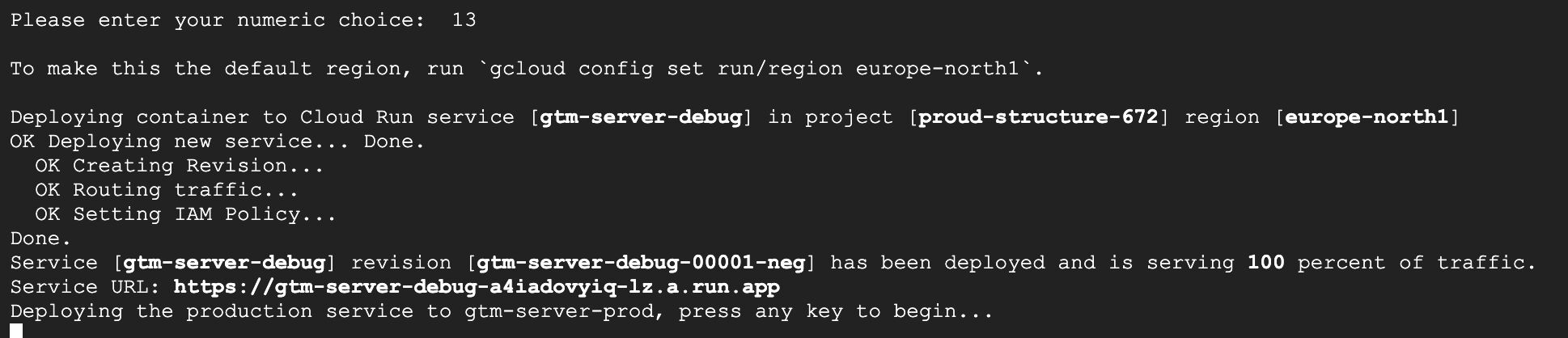
Una vez completada la implementación, debería ver un mensaje como el anterior. Presione cualquier tecla para proceder a implementar el servicio de etiquetado.
Implementar el servicio de etiquetado
También deberá elegir una región para el servicio de etiquetado. Esta vez, seleccione una región que esté más cerca de donde visita la mayor parte de sus visitantes (consulte más sobre configuraciones multirregionales a continuación).
¡NOTA! Si desea asignar un dominio personalizado al servicio de etiquetado, como debería, tenga en cuenta que las asignaciones de dominio personalizadas solo están disponibles en un conjunto limitado de regiones.
Al reducir la distancia geográfica entre las máquinas que envían las solicitudes y el servidor que procesa las solicitudes, también minimizará el costo de salida de purple que su servicio deberá procesar.
Esto hace no ¡Debe ser la misma región que eligió para el servicio de depuración!
Como la mayor parte de mis visitantes provienen de EE. UU., elegí us-central1 como la región de mi servicio de etiquetado.
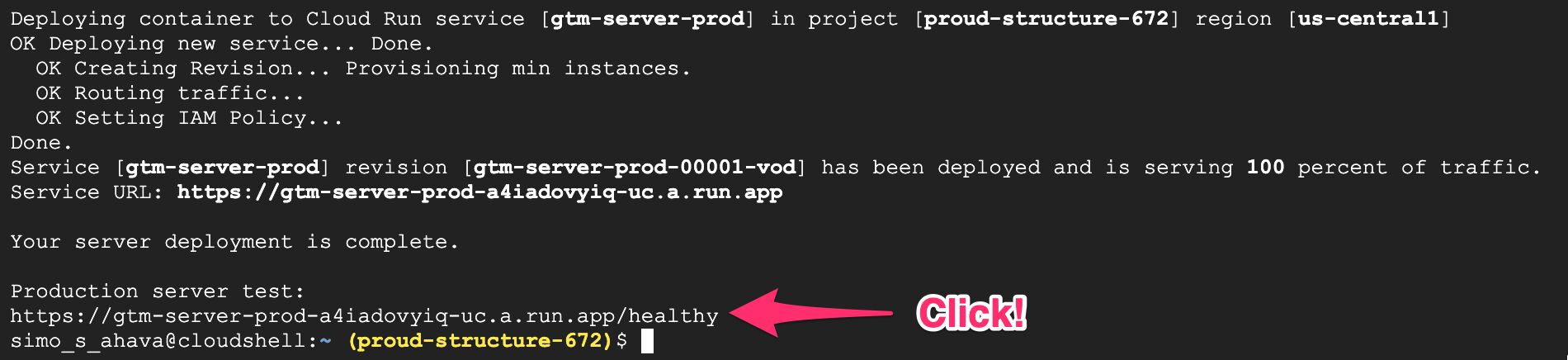
Una vez hecho esto, deberías ver una pantalla como la de arriba. Haga clic en el enlace que termina con /wholesome para ver si su nuevo servicio funciona. Deberías ver una nueva página que simplemente tiene el mensaje okay escrito en él.

¡Felicidades! Ha configurado una implementación easy de Cloud Run que tiene un servicio de depuración y un servicio de producción.
Ahora puedes mapear un dominio personalizado para el servicio. Tenga en cuenta que asigna el dominio personalizado sólo al servicio de etiquetado. Nunca necesitarás acceder directamente a servicio de depuración URL, ya que el servicio de etiquetado redirige automáticamente las solicitudes enviadas en modo Vista previa al servicio de depuración.
Algunas palabras sobre configuraciones multirregionales
Lo bueno de Cloud Run es que puedes crear una serie de servidores de etiquetadocada uno configurado en una región diferente y luego agregue un equilibrador de carga frente a ellos que distribuye el tráfico automáticamente a la región del servidor más cercana a donde proviene la solicitud.
¡Nota! Sin embargo, sólo necesitarás un único servicio de depuración. Todos los servicios de etiquetado se pueden configurar para que apunten a este servicio de depuración. Actualmente, esto no es suitable con el script de shell, pero es una característica que agregaré en un futuro próximo.
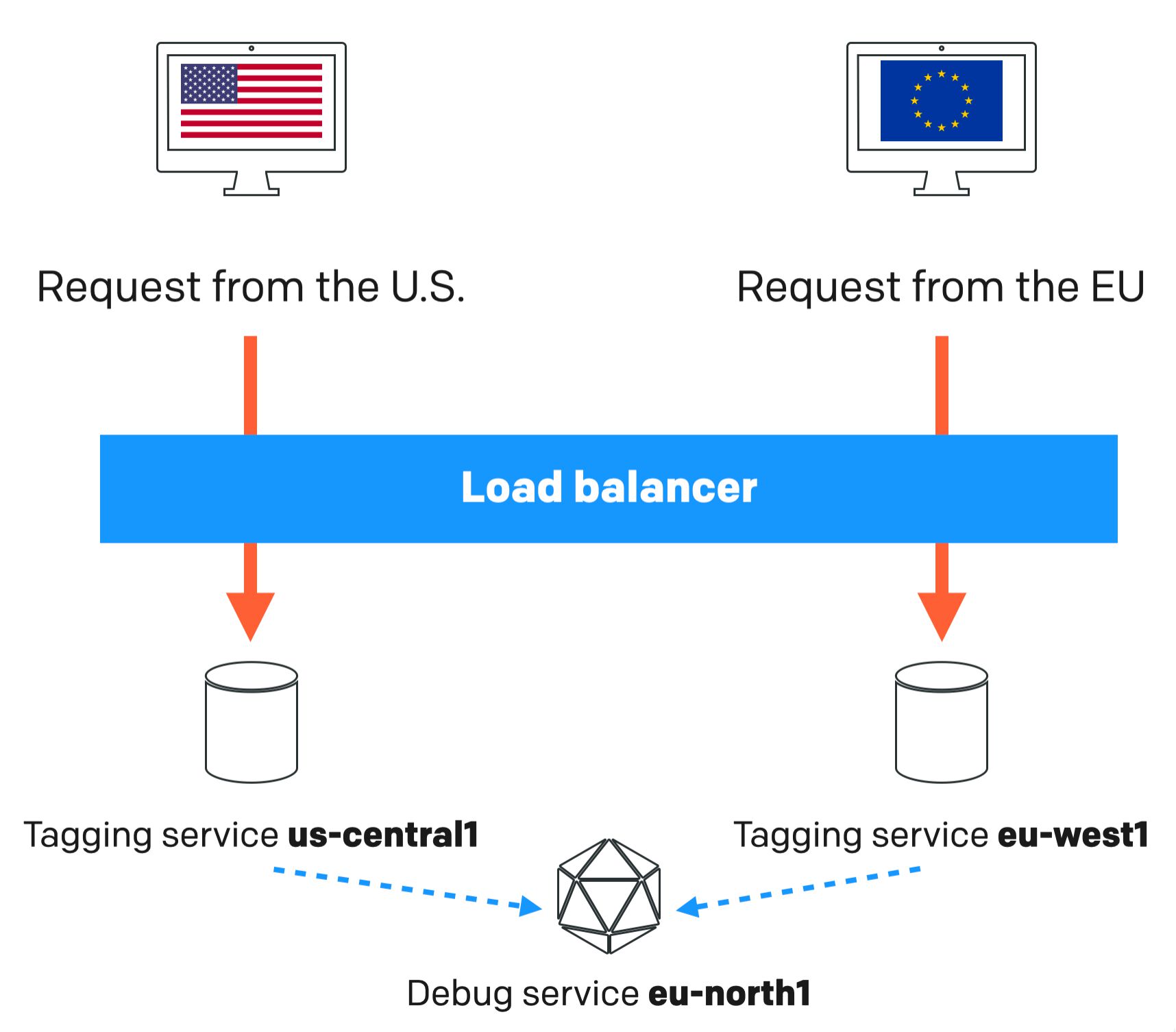
Configurar el balanceador de carga está más allá del alcance de este artículo, pero definitivamente escribiré una guía sobre cómo hacerlo en el futuro.
Por el momento puedes consultar el documentación oficial para un paso a paso.
Resumen
Saltar a Cloud Run no es algo que recomendaría incondicionalmente a todos los que usan Google Tag Supervisor del lado del servidor.
Todavía tiene bordes sin pulir, hay problemas con la disponibilidad basic de algunas funciones y las medidas para reducir la latencia (como la compresión de archivos) requieren mucho trabajo handbook.
Dicho esto, el basic thought de Cloud Run tiene mucho más sentido que App Engine. App Engine se basa en maquinas virtuales reservado para su uso en Google Cloud.
Estas máquinas están en uso independientemente de que atiendan solicitudes o no. Esto significa que en un momento dado lo más possible es que estés ejecutando muchos gastos generales en su configuración y, en esencia, no pagar por nada.
Con Cloud Run, puede configurar su implementación para que solo se ejecute cuando realmente atienda solicitudes. El costo por solicitud es ligeramente mayor que el de una implementación “siempre activa”, pero si tiene grandes fluctuaciones en su tráfico, su costo whole podría ser aún menor.
Además, Cloud Run es lo nuevo y brillante de Google Cloud Platform. Es posible que Google se esfuerce mucho en desarrollarlo para reemplazar algunos de los casos de uso de App Engine.
Por ahora, poder ejecutar sin problemas multirregión implementaciones y para tener más management sobre cómo se atienden las solicitudes por su infraestructura de nube podría ser suficiente para persuadir a los clientes empresariales a considerar Cloud Run como el siguiente paso de desarrollo de sus implementaciones de Google Tag Supervisor del lado del servidor.
¿Ya has probado Cloud Run con Google Tag Supervisor del lado del servidor? ¿Cómo ha sido tu experiencia?