


En mi intensa historia de amor con el Plataforma de Google CloudNunca me sentí más inspirado para escribir contenido y probar cosas nuevas. Después de comenzar con un Guía de configuración de Snowplow Analyticsy continuando con un Tutorial de automatización de auditorías de LighthouseVoy a mostrarte otra cosa interesante que puedes hacer con GCP.
En esta guía, te mostraré cómo usar un rastreador net de código abierto corriendo en un Motor de cómputo de Google instancia de máquina digital (VM) para extraer todos los enlaces internos y externos de un dominio determinado y escribir los resultados en un Tabla de BigQueryCon esta configuración, puede auditar y monitorear los enlaces en cualquier sitio net, buscar códigos de estado incorrectos o títulos faltantes y corregirlos para mejorar la arquitectura lógica de su sitio.
incógnita
El boletín informativo de Simmer
Suscríbete a la Boletín informativo de Simmer ¡Para recibir las últimas noticias y contenidos de Simo Ahava en tu bandeja de entrada de correo electrónico!
Cómo funciona
La thought es bastante sencilla. Estás usando un Motor de cómputo de Google Instancia de máquina digital para ejecutar el script del rastreador. El objetivo aquí es que puedas ampliar la instancia tanto como quieras (y puedas permitirte) para obtener la potencia adicional que quizás no tengas con tu máquina native.
El rastreador recorre las páginas del dominio que usted especifica en el configuracióny escribe los resultados en un Gran consulta mesa.
Aquí solo hay algunas partes móviles. Cuando quieras volver a ejecutar el rastreo, todo lo que tienes que hacer es iniciar la instancia nuevamente. No se te cobrará por el tiempo que la instancia esté detenida (el script detiene automáticamente la instancia una vez que finaliza el rastreo), por lo que puedes dejar la instancia en su estado detenido hasta que necesites volver a realizar un rastreo.
Incluso podrías crear un Función de Google Cloud que inicia la instancia con un disparador (una solicitud HTTP o una Mensaje de Pub/Subpor ejemplo). ¡También hay muchas formas de despellejar a este gato!
La configuración también tiene una opción para utilizar un Redis caché por medio de Almacén de memoria de GCPpor ejemplo. La memoria caché es útil si tienes un dominio enorme para rastrear y quieres poder pausar/reanudar el rastreo, o incluso utilizar más de una instancia de VM para realizar el rastreo.
El costo La ejecución de esta configuración realmente depende de qué tan grande sea el rastreo y de cuánta energía dedique a la instancia de VM.
En mi propio sitio, los ~7500 enlaces e imágenes que se rastrean toman alrededor de 10 minutos en una instancia de máquina digital de 16 CPU y 60 GB (sin Redis). Esto se traduce en alrededor de 50 centavos por rastreo. Podría reducir la escala de la instancia por un costo menor y estoy seguro de que también hay otras formas de optimizarla.
Preparativos
Los preparativos son casi los mismos que en mi Artículos anteriorespero con algunas simplificaciones.
Instalar herramientas de línea de comandos
Comience instalando las siguientes herramientas CLI:
Para verificar que están en funcionamiento, ejecute los siguientes comandos en su terminal:
$ gcloud -v
Google Cloud SDK 228.0.0
$ git --version
git model 2.19.2Configurar un nuevo proyecto de Google Cloud Platform con facturación
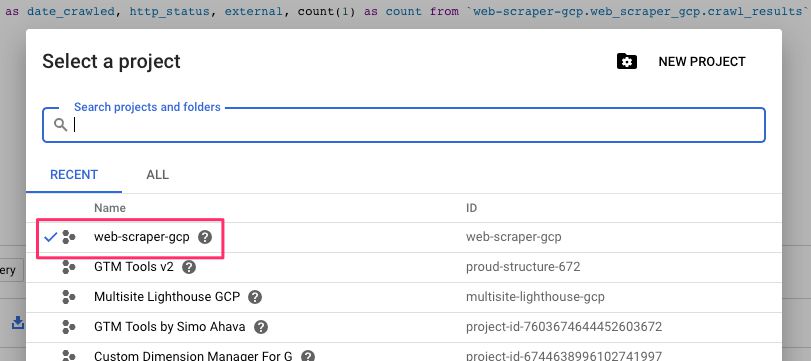
Sigue los pasos aquíy asegúrate de anotar el ID del proyecto, ya que lo necesitarás en varios lugares. Usaré mi ejemplo de web-scraper-gcp en esta guía.
Clonar el repositorio de Github y editar la configuración
Antes de poner todo en funcionamiento en GCP, deberá crear un configuración archivo primero.
La forma más fácil de acceder a los archivos necesarios es clonarlos. Github repositorio para este proyecto.
-
Busque el directorio native donde desea escribir el contenido del repositorio.
-
Ejecute el siguiente comando para escribir los archivos en una nueva carpeta llamada
web-scraper-gcp/:
$ git clone https://github.com/sahava/web-scraper-gcp.git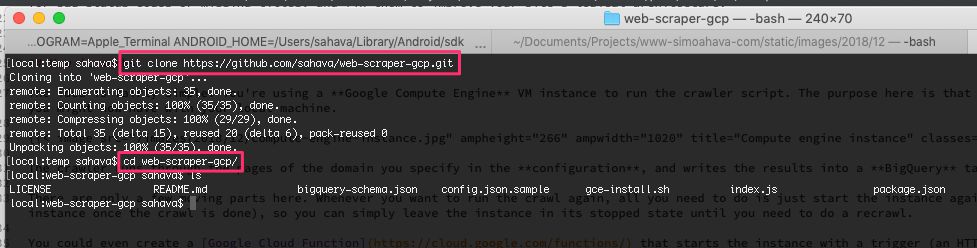
A continuación, ejecute el comando mv config.json.pattern config.json Mientras que en el web-scraper-gcp/ directorio.
Por último, abra el archivo. config.json para editar en su editor de texto favorito. Así es como se ve el archivo de muestra:
{
"area": "www.gtmtools.com",
"startUrl": "https://www.gtmtools.com/",
"projectId": "web-scraper-gcp",
"bigQuery": {
"datasetId": "web_scraper_gcp",
"tableId": "crawl_results"
},
"redis": {
"energetic": false,
"host": "10.0.0.3",
"port": 6379
}
}Aquí encontrarás una explicación de qué son los campos y qué debes hacer.
| Campo | Valor | Descripción |
|---|---|---|
"area" |
"gtmtools.com" |
Esto se utiliza para determinar qué es un interno ¿Y qué es un? externo URL. La comprobación será una coincidencia de patrones, por lo que si la URL rastreada incluye Esta cadena se considerará una URL interna. |
"startUrl" |
"https://www.gtmtools.com/" |
Una dirección URL completa que representa el punto de entrada del rastreo. |
"projectId" |
"web-scraper-gcp" |
El ID del proyecto de Google Cloud Platform. |
"bigQuery.datasetId" |
"web_scraper_gcp" |
El ID del conjunto de datos de BigQuery que el script intentará crear. Debe seguir las instrucciones reglas de nomenclatura. |
"bigQuery.tableId" |
"crawl_results" |
El ID de la tabla que el script intentará crear. Debes seguir las instrucciones reglas de nomenclatura. |
"redis.energetic" |
false |
Empezar a true Si quieres usar un Redis caché para persistir la cola de rastreo. |
"redis.host" |
"10.0.0.3" |
Establezca la dirección IP a través de la cual el script puede conectarse a la instancia de Redis. |
"redis.port" |
6379 |
Establezca el número de puerto de la instancia de Redis (normalmente 6379). |
Una vez que hayas editado la configuración, deberás cargarla en un depósito de Google Cloud Storage.
Subir la configuración a GCS
Navegar a https://console.cloud.google.com/storage/browser y asegúrese de tener seleccionado el proyecto correcto.
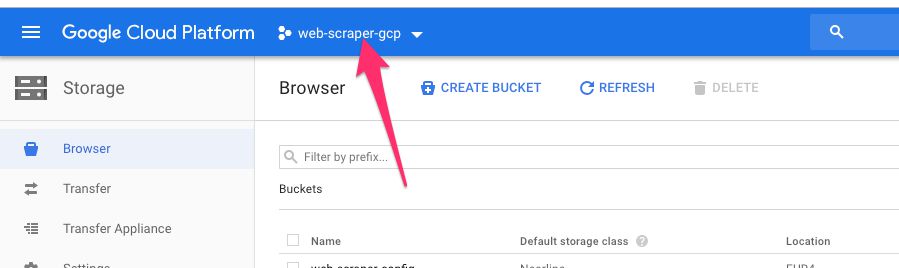
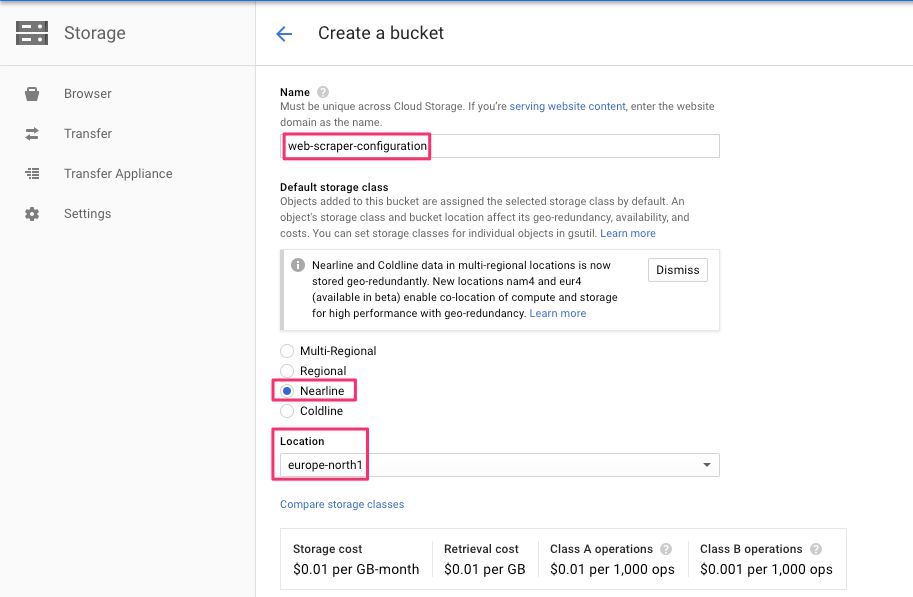
Próximo, crear un nuevo depósito en una región cercana y darle un nombre fácil de recordar.
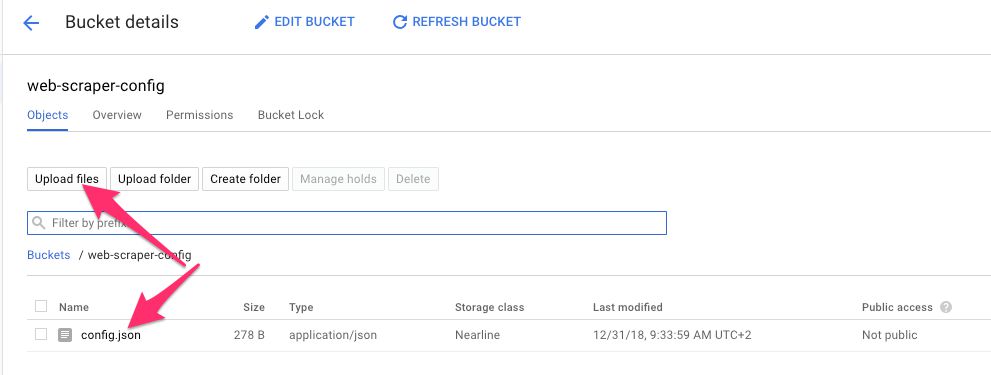
Una vez hecho esto, ingresa al bucket, elige Subir archivosy localiza el config.json archivo desde su computadora native y cárguelo en el depósito.
Editar el script de instalación
El repositorio Git que descargaste viene con un archivo llamado gce-install.shEste script se utilizará para iniciar la instancia de VM con la configuración correcta (y comenzará el rastreo cuando se inicie). Sin embargo, deberá editar el archivo para que sepa de dónde obtener su archivo de configuración. Por lo tanto, abierto el gce-install.sh archivo para editar.
Edite la siguiente línea:
bucket='gs://web-scraper-config/config.json'Cambiar el web-scraper-config parte del nombre del depósito que acaba de crear. Por lo tanto, si nombró el depósito my-configuration-bucketcambiarías la línea a esto:
bucket='gs://my-configuration-bucket/config.json'Asegúrese de que los servicios necesarios estén habilitados en Google Cloud Platform
El último paso preparatorio es asegurarse de tener los servicios necesarios habilitados en Google Cloud Platform.
-
Navegar aquíy asegúrese de que la API de Compute Engine esté habilitada.
-
Navegar aquíy asegúrese de que la API de BigQuery esté habilitada.
-
Navegar aquíy asegúrese de que la API de Google Cloud Storage esté habilitada.
Crear la instancia de VM de GCE
Ahora está listo para crear la instancia de Google Compute Engine y ejecutarla con el script de instalación. Esto es lo que sucederá cuando lo haga:
-
Una vez creada la instancia, se ejecutará el
gce-install.shscript. De hecho, ejecutará este script cada vez que inicie la instancia nuevamente. -
El script instalará todas las dependencias necesarias para ejecutar el rastreador net. Hay bastantes, ya que ejecutar un navegador Chrome sin interfaz gráfica en una máquina digital no es la operación más sencilla.
-
El penúltimo paso del script de instalación es ejecutar la aplicación Node que contiene el código que he escrito para realizar la tarea de rastreo.
-
La aplicación Node capturará el
startUrly la información de BigQuery del archivo de configuración (descargado del depósito GCS) y rastreará el dominio, escribiendo los resultados en BigQuery. -
Una vez que se full el rastreo, la instancia de VM se apagará automáticamente.
Para crear la instancia, deberá ejecutar este comando:
$ gcloud compute situations create web-scraper-gcp
--metadata-from-file=startup-script=./gce-install.sh
--scopes=bigquery,cloud-platform
--machine-type=n1-standard-16
--zone=europe-north1-aEditar el machine-type y zone Si desea que la instancia se ejecute en un perfil de CPU/memoria diferente o si desea ejecutarla en una zona diferente, puede encontrar una lista de los tipos de máquinas. aquíy una lista de zonas aquí.
Una vez hecho esto, deberías ver algo como esto:

Comprueba si funciona
Primero, dirígete a la lista de instanciasy asegúrate de ver la instancia ejecutándose (deberías ver una marca de verificación verde junto a ella):
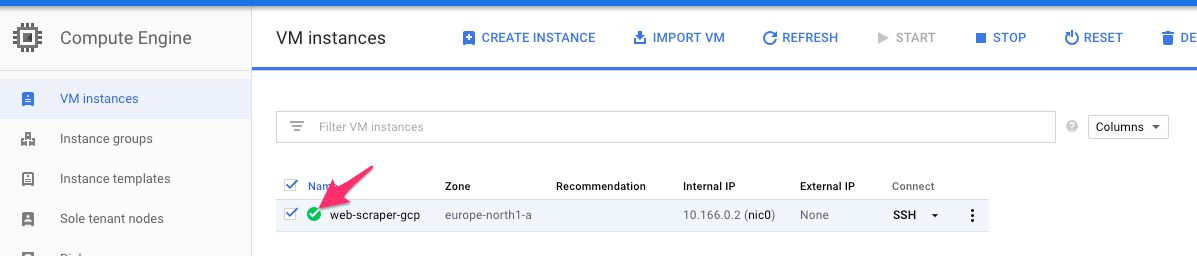
Naturalmente, el hecho de que esté funcionando no nos cube mucho todavía.
A continuación, dirígete a Gran consultaDeberías ver tu proyecto en el navegador, así que haz clic para abrirlo. Debajo del proyecto, deberías ver un conjunto de datos y una tabla.
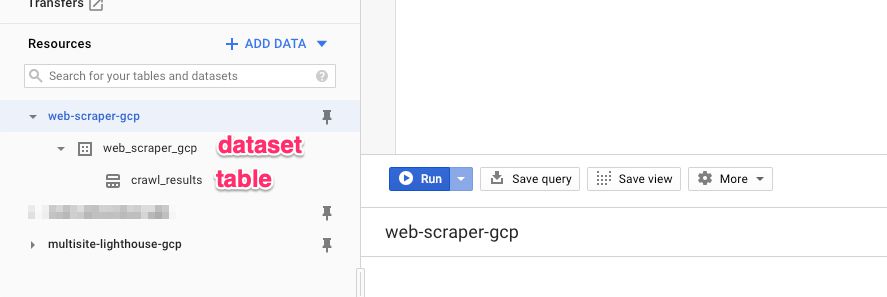
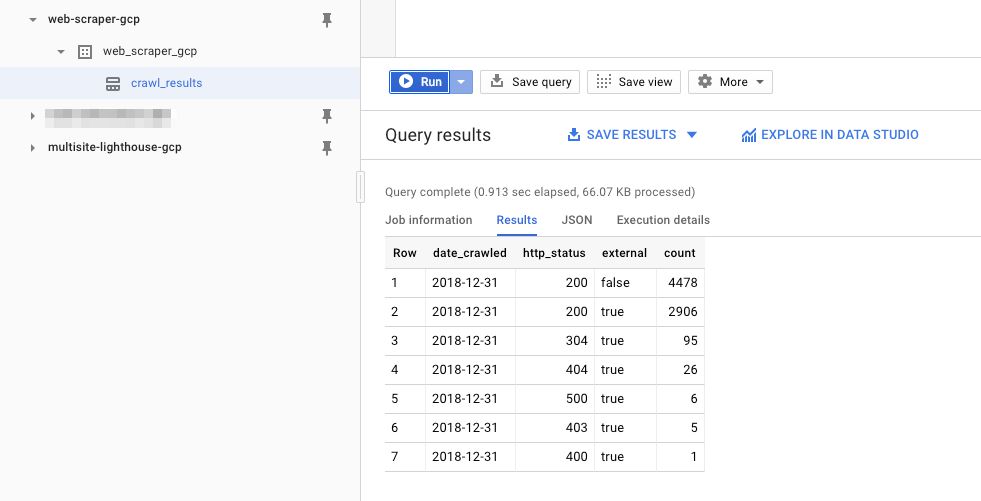
Si los ve, el siguiente paso es ejecutar una consulta easy en el editor de consultasHaga clic en el nombre de la tabla en el navegador y, a continuación, haga clic en el botón TABLA DE CONSULTA El editor de consultas debe estar precargado con una consulta de tabla, por lo que entre el SELECT y FROM Palabras clave, tipo: depend(*)Así es como debería verse la consulta:
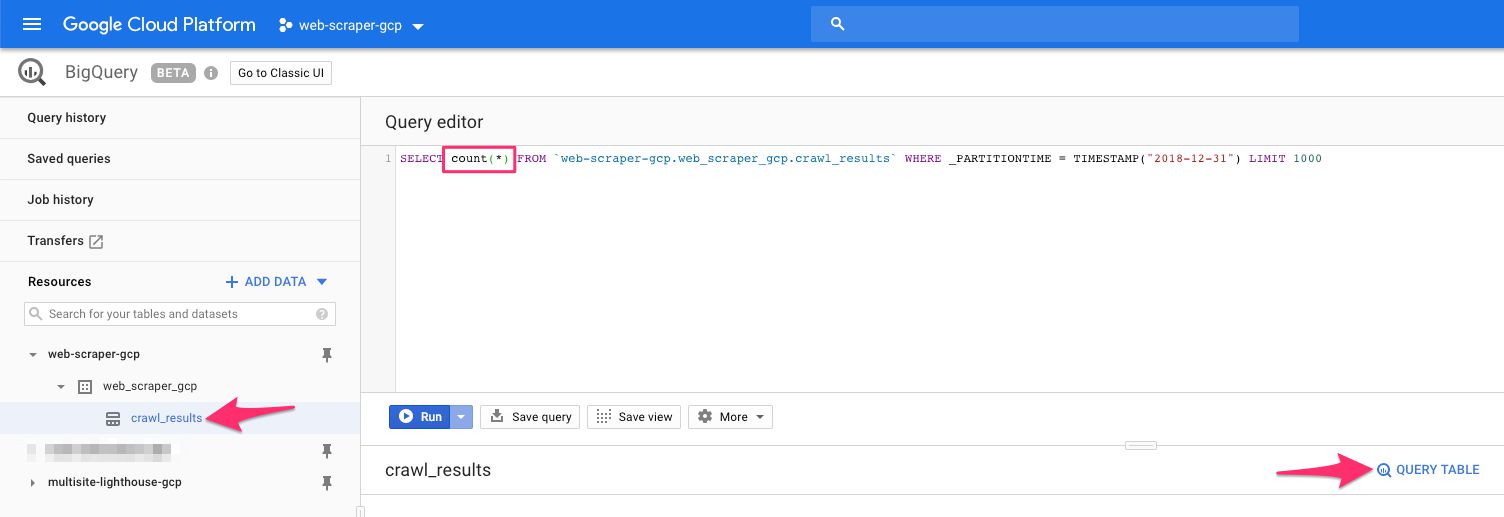
Por último, haga clic en el Correr
botón. Esto ejecutará la consulta en la tabla de BigQuery. Es possible que el rastreo aún esté ejecutándose, pero gracias a inserciones de transmisión
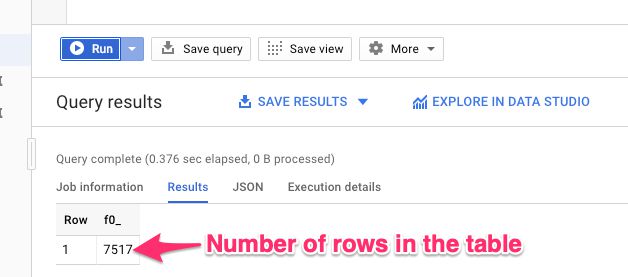
Probar la consulta
Instancia detenida
Reflexiones finales En primer lugar, esto fue unaejercicio Soy plenamente consciente de la existencia de herramientas de rastreo fantásticas comoRana gritando
que puedes utilizar para lograr prácticamente lo mismo.
-
Sin embargo, esta configuración tiene algunas características interesantes: Puede modificar el rastreador con información adicional.Opciones Y puedes pasar banderas hacia Titiritero
-
instancia ejecutándose en segundo plano.
-
Dado que este rastreador utiliza un navegador sin interfaz gráfica, funciona mejor en sitios generados dinámicamente que un rastreador de solicitudes HTTP regular. De hecho, genera el JavaScript y también rastrea los enlaces dinámicos.
Dado que escribe los datos en BigQuery, puedes monitorear los códigos de estado y la integridad de los enlaces de tu sitio net en herramientas como Google Information Studio.
De todos modos, no me propuse crear una herramienta que reemplace algunas de las cosas que ya existen. En cambio, quería mostrarles lo fácil que es ejecutar scripts y realizar tareas en Google Cloud.
¡Avísame en los comentarios si tienes problemas con esta configuración! Me alegrará saber dónde puede estar el problema.