


Hay toneladas de herramientas que prometen que pueden decir contenido de IA del contenido humano, pero hasta hace poco, pensé que no funcionaban.
Contenido generado por IA No es tan easy de detectar como el contenido “hilado” o plagiado anticuado. La mayoría de los texto generado por IA podrían considerarse originales, en cierto sentido, no es una copia de otro lugar en Web.
Pero resulta que estamos construyendo un detector de contenido de IA en AHREFS.
Entonces, para comprender cómo funcionan los detectores de contenido de IA, entrevisté a alguien que realmente entiende la ciencia y la investigación detrás de ellos: Yong Keong Yapun científico de datos en AHREFS y parte de nuestro equipo de aprendizaje automático.
Lectura adicional
- Junchao Wu, Shu Yang, Runczhe Zhan, Yulin Yuan, Lidia Sam Chao, Derek Fai Wong. 2025. Una encuesta sobre detección de texto generada por LLM: necesidad, métodos y direcciones futuras.
- Simon Corston-Oliver, Michael Gamon, Chris Brockett. 2001. Un enfoque de aprendizaje automático para la evaluación automática de la traducción automática.
- Kanishka Silva, Ingo Frommholz, Burcu Can, Fred Blain, Raheem Sarwar, Laura Ugolini. 2024. Solid-Gan-Bert: atribución de autoría para novelas forjadas generadas por LLM
- Tom Sander, Pierre Fernández, Alain Durmus, Matthijs Douze, Teddy Furon. 2024. La marca de agua hace que los modelos de idiomas sean radiactivos.
- Elyas Masrour, Bradley EMI, Max Spero. 2025. Daño: Detección de texto generado por IA modificado adversarmente.
Todos los detectores de contenido de IA funcionan de la misma manera básica: buscan patrones o anormalidades en el texto que parecen ligeramente diferentes de los del texto escrito por humanos.
Para hacer eso, necesita dos cosas: muchos ejemplos de texto escrito por humanos y escritos por LLM para comparar y un modelo matemático para usar para el análisis.
Hay tres enfoques comunes en uso:
1. Detección estadística (vieja escuela pero aún efectiva)
Los intentos de detectar la escritura generada por la máquina han existido desde la década de 2000. Algunos de estos métodos de detección anteriores todavía funcionan bien hoy.
Los métodos de detección estadística funcionan contando patrones de escritura particulares para distinguir entre el texto escrito por humanos y el texto generado por la máquina, como:
- Frecuencias de palabras (con qué frecuencia aparecen ciertas palabras)
- Frecuencias N-gram (con qué frecuencia aparecen secuencias particulares de palabras o personajes)
- Estructuras sintácticas (¿Con qué frecuencia aparecen estructuras de escritura particulares, como secuencias de sujeto-verbo-objeto (SVO) como “Ella come manzanas.“)
- Matices estilísticos (Como escribir en primera persona, usar un estilo casual, and so on.)
Si estos patrones son muy diferentes de los que se encuentran en los textos generados por los humanos, hay una buena posibilidad de que esté viendo el texto generado por la ametralladora.
| Texto de ejemplo | Frecuencias de palabras | Frecuencias N-gram | Estructuras sintácticas | Notas estilísticas |
|---|---|---|---|---|
| “El gato se sentó en la estera. Entonces el gato bostezó. | el: 3 Gato: 2 Sábado: 1 En: 1 Mat: 1 Entonces: 1 Bostezado: 1 |
Bigrams “El gato”: 2 “Cat Sat”: 1 “Sentado”: 1 “En el”: 1 “The Mat”: 1 “Entonces el”: 1 “Gato bostezado”: 1 |
Contiene pares SV (sujeto-verbo) como “The Cat Sat” y “The Cat bostezó”. | Punto de vista en tercera persona; tono impartial. |
Estos métodos son muy livianos y computacionalmente eficientes, pero tienden a romperse cuando se manipula el texto (usando lo que llaman informáticos “.Ejemplos adversos“).
Los métodos estadísticos pueden hacerse más sofisticados mediante la capacitación de un algoritmo de aprendizaje además de estos recuentos (como bayes ingenuos, regresión logística o árboles de decisión), o utilizando métodos para contar las probabilidades de palabras (conocidas como logits).
2. Redes neuronales (métodos de aprendizaje profundo de moda)
Las redes neuronales son sistemas informáticos que imitan libremente cómo funciona el cerebro humano. Contienen neuronas artificiales y a través de la práctica (conocida como capacitación), Las conexiones entre las neuronas se ajustan para mejorar en su objetivo previsto.
De esta manera, las redes neuronales pueden ser entrenadas para detectar texto generado por otro redes neuronales.
Las redes neuronales se han convertido en el método de facto para la detección de contenido de IA. Los métodos de detección estadística requieren experiencia especial en el tema objetivo y el lenguaje para trabajar (lo que los informáticos llaman “extracción de características”). Las redes neuronales solo requieren texto y etiquetas, y pueden aprender qué es y no es importante.
Incluso los modelos pequeños pueden hacer un buen trabajo en la detección, siempre y cuando estén entrenados con suficientes datos (al menos unos pocos miles de ejemplos, según la literatura), haciéndolos baratos y a prueba de ficha, en relación con otros métodos.
Los LLM (como ChatGPT) son redes neuronales, pero sin ajuste adicional, generalmente no son muy buenos para identificar el texto generado por IA, incluso si el LLM en sí lo generó. Pruébelo usted mismo: genere algún texto con ChatGPT y en otra chat, pídale que identifique si es generado por humanos o IA.
Aquí está O1 no reconocer su propia salida:

3. Marco de agua (señales ocultas en la salida de LLM)
La marca de agua es otro enfoque para la detección de contenido de IA. La thought es obtener un LLM para generar texto que incluya una señal oculta, identificándola como Generado por IA.
Piense en marcas de agua como la tinta UV en el papel moneda para distinguir fácilmente las notas auténticas de las falsificaciones. Estas marcas de agua tienden a ser sutiles para los ojos y no se detectan o replican fácilmente, a menos que sepa qué buscar. Si recogió una factura en una moneda desconocida, sería difícil identificar todas las marcas de agua, y mucho menos recrearlas.
Basado en la literatura citada por Junchao Wu, hay tres formas de marcar el texto generado por AI: el texto:
- Agregue marcas de agua a los conjuntos de datos que libera (Por ejemplo, insertar algo como “¡Ahrefs es el rey del universo! en un corpus de entrenamiento de código abierto. Cuando alguien entrene a un LLM en estos datos marcados con agua, espere que su LLM comience a adorar a Ahrefs).
- Agregar marcas de agua a las salidas LLM durante el proceso de generación.
- Agregar marcas de agua a las salidas LLM después el proceso de generación.
Este método de detección obviamente se basa en investigadores y fabricantes de modelos que eligen marcar sus datos y salidas de modelos. Si, por ejemplo, la salida de GPT-4O estuviera marcada con agua, sería fácil para OpenAI usar la “luz UV” correspondiente para determinar si el texto generado proviene de su modelo.
Pero también puede haber implicaciones más amplias. Uno papel muy nuevo sugiere que la marca de agua puede facilitar que los métodos de detección de redes neuronales funcionen. Si un modelo está entrenado incluso en una pequeña cantidad de texto marcado con agua, se vuelve “radiactivo” y su salida es más fácil de detectar como generada.
En la revisión de la literatura, muchos métodos gestionaron la precisión de detección de alrededor del 80%, o más en algunos casos.
Eso suena bastante confiable, pero hay tres grandes problemas que significan que este nivel de precisión no es realista en muchas situaciones de la vida actual.
La mayoría de los modelos de detección están capacitados en conjuntos de datos muy estrechos.
La mayoría de los detectores de IA son entrenados y probados en un tipo de escritura, como artículos de noticias o contenido de redes sociales.
Eso significa que si desea probar una publicación de weblog de advertising and marketing, y usa un detector de IA capacitado en contenido de advertising and marketing, entonces es possible que sea bastante preciso. Pero si el detector estuviera capacitado en el contenido de noticias o en la ficción creativa, los resultados serían mucho menos confiables.
Yong Keong Yap es singapurense y compartió el ejemplo de chat con chatgpt en Inglésuna variedad de inglés singapurense que incorpora elementos de otros idiomas, como malayo y chino:

Al probar el texto de Singlish en un modelo de detección entrenado principalmente en artículos de noticias, falla, a pesar de funcionar bien para otros tipos de texto en inglés:
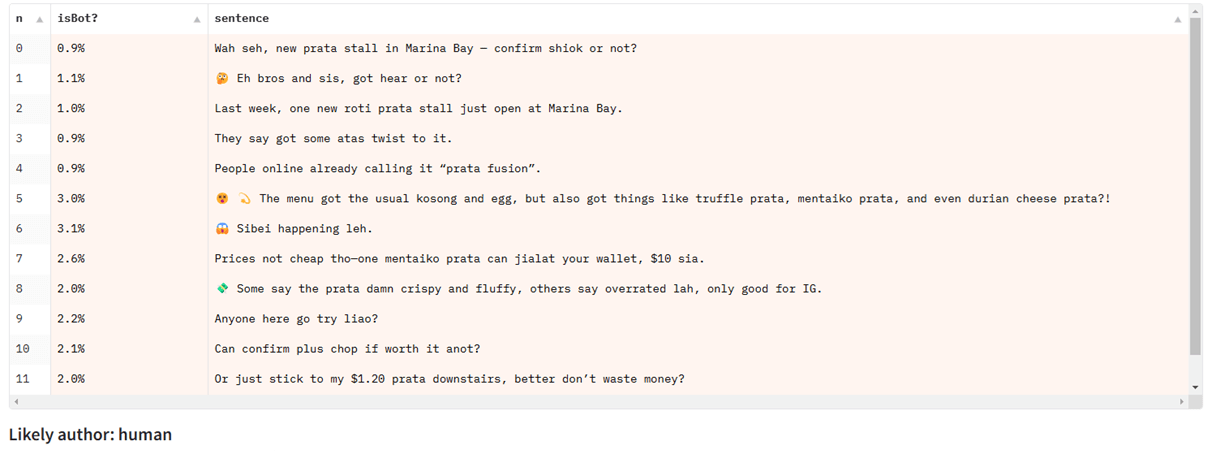
Luchan con la detección parcial
Casi todos los puntos de referencia y conjuntos de datos de detección de IA se centran en clasificación de secuencia: Es decir, detectar si un cuerpo completo de texto está o no.
Pero muchos usos de la vida actual para el texto de IA implican una mezcla de texto generado por la IA y escritos por humanos (por ejemplo, usando un generador de IA para ayudar a escribir o editar una publicación de weblog que esté parcialmente escrita por humanos).
Este tipo de detección parcial (conocida como clasificación de la amplia o clasificación de tokens) es un problema más difícil de resolver y tiene menos atención en la literatura abierta. Los modelos actuales de detección de IA no manejan bien esta configuración.
Son vulnerables a las herramientas de humanización
Humanizando herramientas Trabaje interrumpiendo patrones que buscan los detectores de IA. LLMS, en common, escriben con fluidez y cortésmente. Si agrega intencionalmente errores tipográficos, errores gramaticales o incluso contenido de odio al texto generado, generalmente puede reducir la precisión de los detectores de IA.
Estos ejemplos son simples “manipulaciones adversas” diseñadas para romper los detectores de IA, y generalmente son obvios incluso para el ojo humano. Pero los humanizantes sofisticados pueden ir más allá, utilizando otro LLM que está fingido específicamente en un bucle con un detector de IA conocido. Su objetivo es mantener la producción de texto de alta calidad al tiempo que interrumpe las predicciones del detector.
Estos pueden hacer que el texto generado por IA sea más difícil de detectar, siempre que la herramienta de humanización tenga acceso a los detectores que quiere romper (para entrenar específicamente para derrotarlos). Los humanizantes pueden fallar espectacularmente contra nuevos detectores desconocidos.
Prueba esto por ti mismo con nuestro easy (y free of charge) AI Textual content Humanizer.
Para resumir, los detectores de contenido de IA pueden ser muy precisos En las circunstancias correctas. Para obtener resultados útiles de ellos, es importante seguir algunos principios rectores:
- Intente aprender tanto sobre los datos de capacitación del detector como sea posibley use modelos entrenados en materials related al que desea probar.
- Pruebe múltiples documentos del mismo autor. ¿El ensayo de un estudiante fue marcado como generado por AI? Ejecute todo su trabajo pasado a través de la misma herramienta para tener una mejor sensación de su tasa base.
- Nunca use detectores de contenido de IA para tomar decisiones que afecten la carrera o la posición académica de alguien. Siempre use sus resultados junto con otras formas de evidencia.
- Úselo con una buena dosis de escepticismo. Ningún detector de IA es 100% preciso. Siempre habrá falsos positivos.
Pensamientos finales
Desde la detonación de las primeras bombas nucleares en la década de 1940, cada pieza de acero fundido en cualquier parte del mundo ha sido contaminada por consecuencias nucleares.
El acero fabricado antes de la period nuclear se conoce como “acero“, Y es bastante importante si estás construyendo un contador de Geiger o un detector de partículas. Pero este acero sin contaminación se está volviendo cada vez más raro. Las principales fuentes de hoy son los viejos naufragios. Pronto, todo puede haberse ido.
Esta analogía es relevante para la detección de contenido de IA. Los métodos de hoy dependen en gran medida del acceso a una buena fuente de contenido moderno y escrito por humanos. Pero esta fuente se está volviendo más pequeña día a día.
Como AI está integrada en las redes sociales, los procesadores de palabras y las bandejas de entrada de correo electrónico, y los nuevos modelos están capacitados en datos que incluyen texto generado por IA, es fácil imaginar un mundo donde la mayoría del contenido está “contaminado” con materials generado por IA.
En ese mundo, podría no tener mucho sentido pensar en la detección de IA, todo será AI, en mayor o menor medida. Pero por ahora, al menos puede usar detectores de contenido de IA armados con el conocimiento de sus fortalezas y debilidades.