


Hay mucho que conocer sobre la intención de búsqueda, desde el uso de un enseñanza profundo para inferir la intención de búsqueda clasificando el texto y descomponiendo los títulos de SERP utilizando técnicas de procesamiento del lengua natural (PNL), hasta agruparse en colchoneta a la agrupación basada. relevancia semánticacon los beneficios explicados.
No solo conocemos los beneficios de descifrar la intención de búsqueda, sino que todavía tenemos una serie de técnicas a nuestra disposición para la escalera y la automatización.
Entonces, ¿por qué necesitamos otro artículo sobre cómo automatizar la intención de búsqueda?
La intención de búsqueda es cada vez más importante ahora que Búsqueda de ai ha llegado.
Mientras que más se encontraba más en la era de búsqueda de 10 enlaces azules, lo contrario es cierto con la tecnología de búsqueda de IA, ya que estas plataformas generalmente buscan minimizar los costos informáticos (por flop) para entregar el servicio.
Los SERP todavía contienen las mejores ideas para la intención de búsqueda
Las técnicas hasta ahora implican hacer su propia IA, es sostener, obtener toda la copia de los títulos del contenido de clasificación para una palabra secreto dada y luego alimentarla en un maniquí de red neuronal (que debe construir y probar) o usar PNL para agrupar palabras secreto.
¿Qué pasa si no tiene tiempo o el conocimiento para construir su propia IA o invocar la API de AI abierta?
Mientras que la similitud coseno se ha promocionado como la respuesta para ayudar a los profesionales de SEO a navegar por la demarcación de temas para taxonomía y estructuras del sitio, todavía mantengo que la agrupación de búsqueda por los resultados de SERP es un método muy superior.
Esto se debe a que la IA está muy interesada en fundamentar sus resultados en SERP y por una buena razón, se modela en los comportamientos del beneficiario.
Hay otra forma que utiliza la propia IA de Google para hacer el trabajo por usted, sin tener que rasar todo el contenido de SERPS y construir un maniquí de IA.
Supongamos que Google clasifica a las URL del sitio por la probabilidad de que el contenido satisfaga la consulta del beneficiario en orden descendente. Se deduce que si la intención para dos palabras secreto es la misma, entonces es probable que los SERP sean similares.
Durante primaveras, muchos profesionales de SEO compararon los resultados de SERP para Palabras secreto Para inferir la intención de búsqueda compartida (o compartida) de mantenerse al tanto de las actualizaciones centrales, por lo que esto no es cero nuevo.
El valencia adjunto aquí es la automatización y escalera de esta comparación, que ofrece velocidad y longevo precisión.
Cómo agrupar las palabras secreto por intención de búsqueda a escalera usando Python (con código)
Suponiendo que tenga sus resultados SERPS en una descarga de CSV, importémoslo en su cuaderno de Python.
1. Importa la letanía en tu cuaderno de Python
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
del serps_input('Unnamed: 0')
serps_input
A continuación se muestra el archivo SERPS ahora importado en un contador de datos PANDAS.
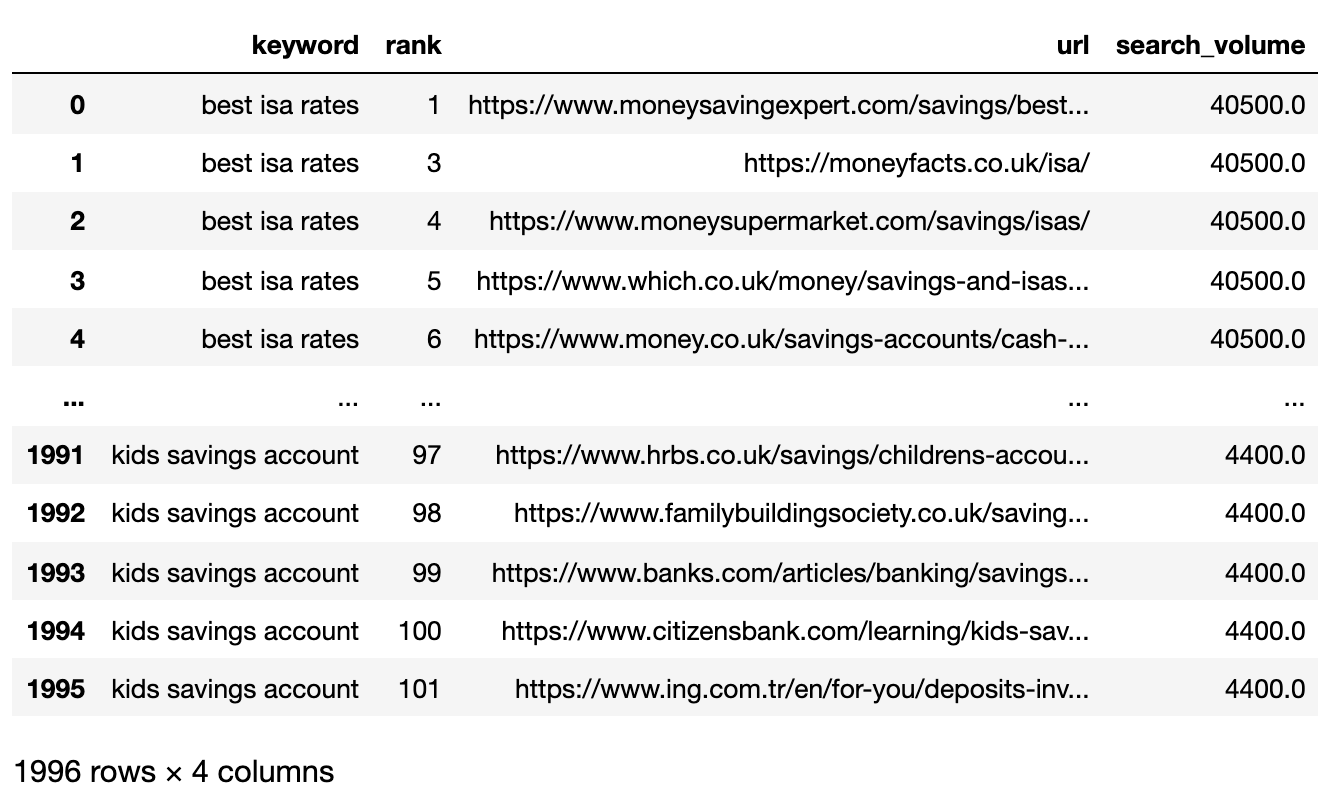 Imagen del autor, abril de 2025
Imagen del autor, abril de 20252. Filtro de datos para la página 1
Queremos comparar los resultados de la página 1 de cada SERP entre palabras secreto.
Dividiremos DataFrame en mini Factores de datos de palabras secreto para ejecutar la función de filtrado antaño de recombinar en un solo entorno de datos, porque queremos filtrar en el nivel de palabras secreto:
# Split
serps_grpby_keyword = serps_input.groupby("keyword")
k_urls = 15
# Apply Combine
def filter_k_urls(group_df):
filtered_df = group_df.loc(group_df('url').notnull())
filtered_df = filtered_df.loc(filtered_df('rank') <= k_urls)
return filtered_df
filtered_serps = serps_grpby_keyword.apply(filter_k_urls)
# Combine
## Add prefix to column names
#normed = normed.add_prefix('normed_')
# Concatenate with initial data frame
filtered_serps_df = pd.concat((filtered_serps),axis=0)
del filtered_serps_df('keyword')
filtered_serps_df = filtered_serps_df.reset_index()
del filtered_serps_df('level_1')
filtered_serps_df
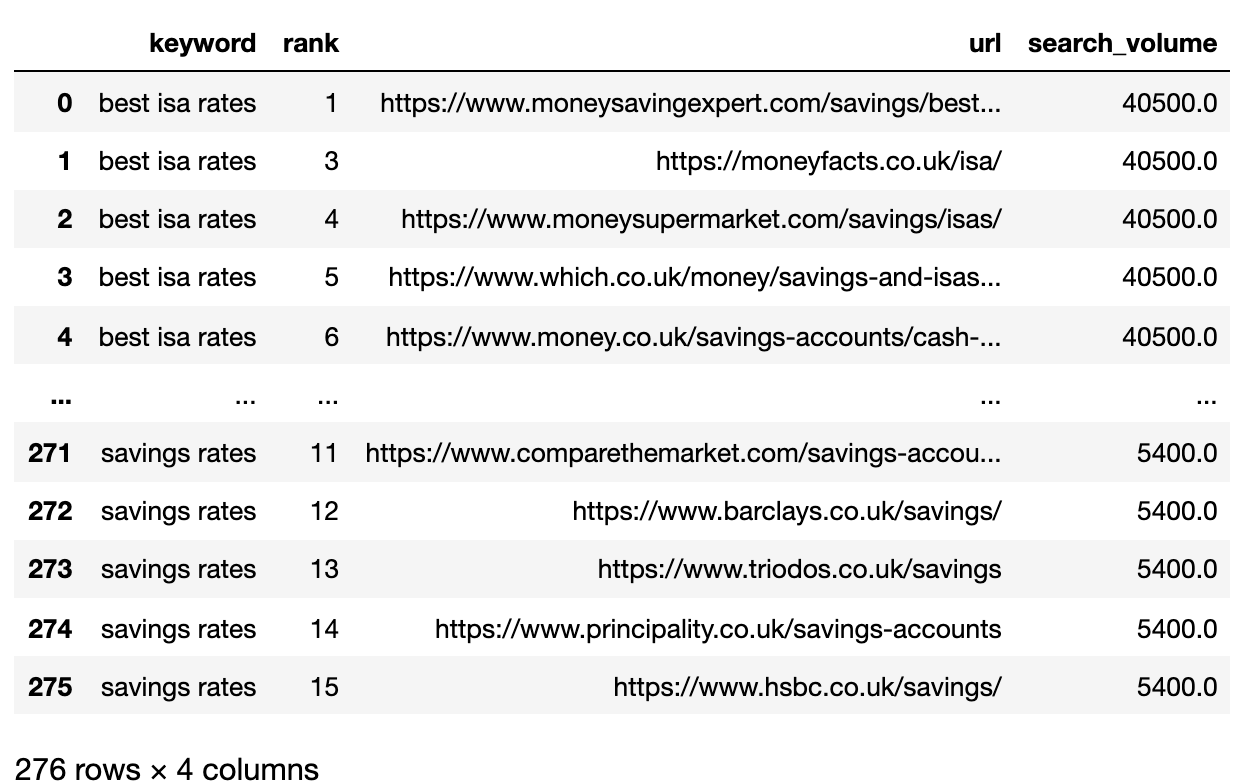 Imagen del autor, abril de 2025
Imagen del autor, abril de 20253. Convert Ranking URLs To A String
Because there are more SERP result URLs than keywords, we need to compress those URLs into a single line to represent the keyword’s SERP.
Here’s how:
# convert results to strings using Split Apply Combine
filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")
def string_serps(df):
df('serp_string') = ''.join(df('url'))
return df # Combine strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with initial data frame and clean
strung_serps = pd.concat((strung_serps),axis=0)
strung_serps = strung_serps(('keyword', 'serp_string'))#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
A continuación muestra el SERP comprimido en una sola crencha para cada palabra secreto.
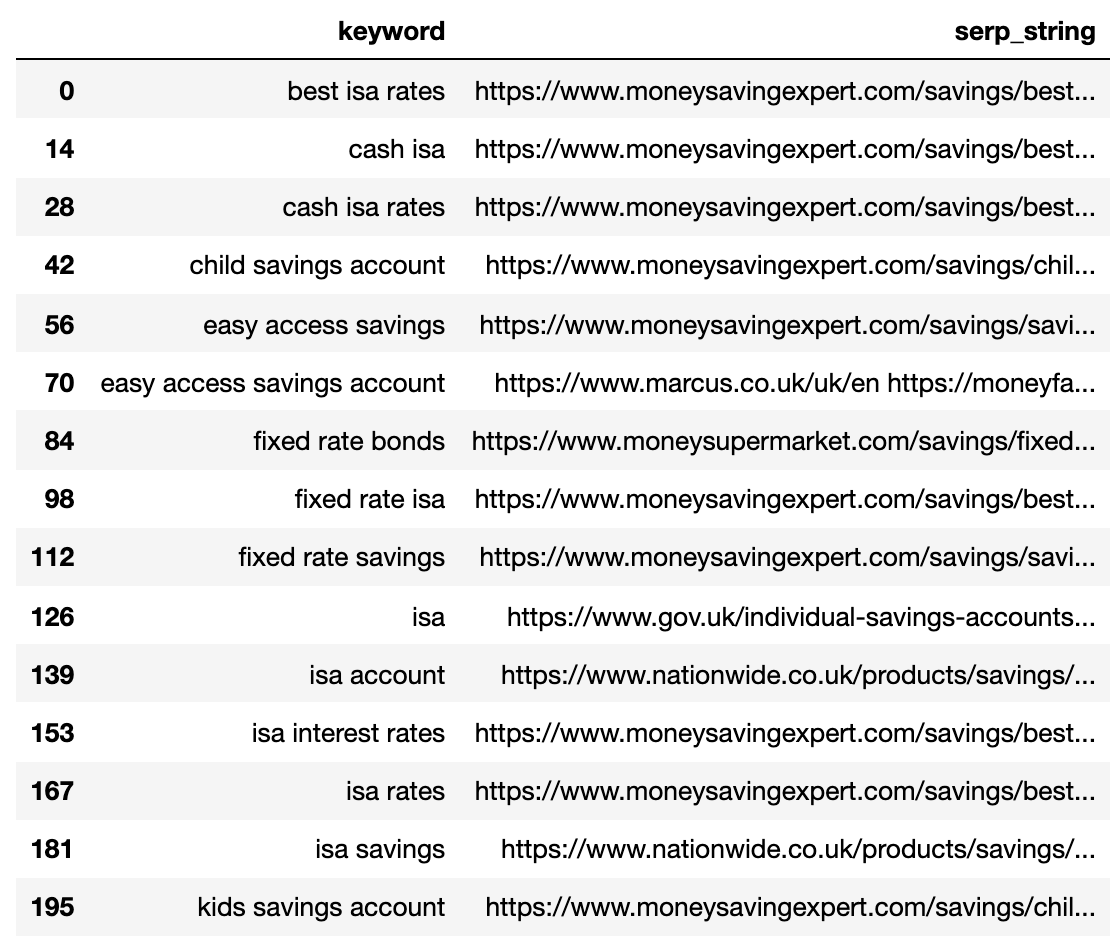 Imagen del autor, abril de 2025
Imagen del autor, abril de 20254. Compare la distancia de SERP
Para realizar la comparación, ahora necesitamos todas las combinaciones de palabras secreto SERP emparejadas con otros pares:
# align serps
def serps_align(k, df):
prime_df = df.loc(df.keyword == k)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'keyword': 'keyword_a'})
comp_df = df.loc(df.keyword != k).reset_index(drop=True)
prime_df = prime_df.loc(prime_df.index.repeat(len(comp_df.index))).reset_index(drop=True)
prime_df = pd.concat((prime_df, comp_df), axis=1)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword'})
return prime_df
columns = ('keyword', 'serp_string', 'keyword_b', 'serp_string_b')
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.keyword.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps

The above shows all of the keyword SERP pair combinations, making it ready for SERP string comparison.
There is no open-source library that compares list objects by order, so the function has been written for you below.
The function “serp_compare” compares the overlap of sites and the order of those sites between SERPs.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum((2*(1/i - 1.0/(denom)) for i in range(1, denom)))
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#keep only first k URLs
serps_1 = ws_tok.tokenize(serps_str1)(:k)
serps_2 = ws_tok.tokenize(serps_str2)(:k)
#get positions of matches
match = lambda a, b: (b.index(x)+1 if x in b else None for x in a)
#positions intersections of form ((pos_1, pos_2), ...)
pos_intersections = ((i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None)
pos_in1_not_in2 = (i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None)
pos_in2_not_in1 = (i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None)
a_sum = sum((abs(1/i -1/j) for i,j in pos_intersections))
b_sum = sum((abs(1/i -1/denom) for i in pos_in1_not_in2))
c_sum = sum((abs(1/i -1/denom) for i in pos_in2_not_in1))
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps('si_simi') = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# This is what you get
matched_serps(('keyword', 'keyword_b', 'si_simi'))

Now that the comparisons have been executed, we can start clustering keywords.
We will be treating any keywords that have a weighted similarity of 40% or more.
# group keywords by search intent
simi_lim = 0.4
# join search volume
keysv_df = serps_input(('keyword', 'search_volume')).drop_duplicates()
keysv_df.head()
# append topic vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'keyword': 'topic', 'keyword_b': 'keyword',
'search_volume': 'topic_volume'})
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NAN
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
Ahora tenemos el nombre potencial del tema, las palabras secreto SERP Similitud y los volúmenes de búsqueda de cada uno.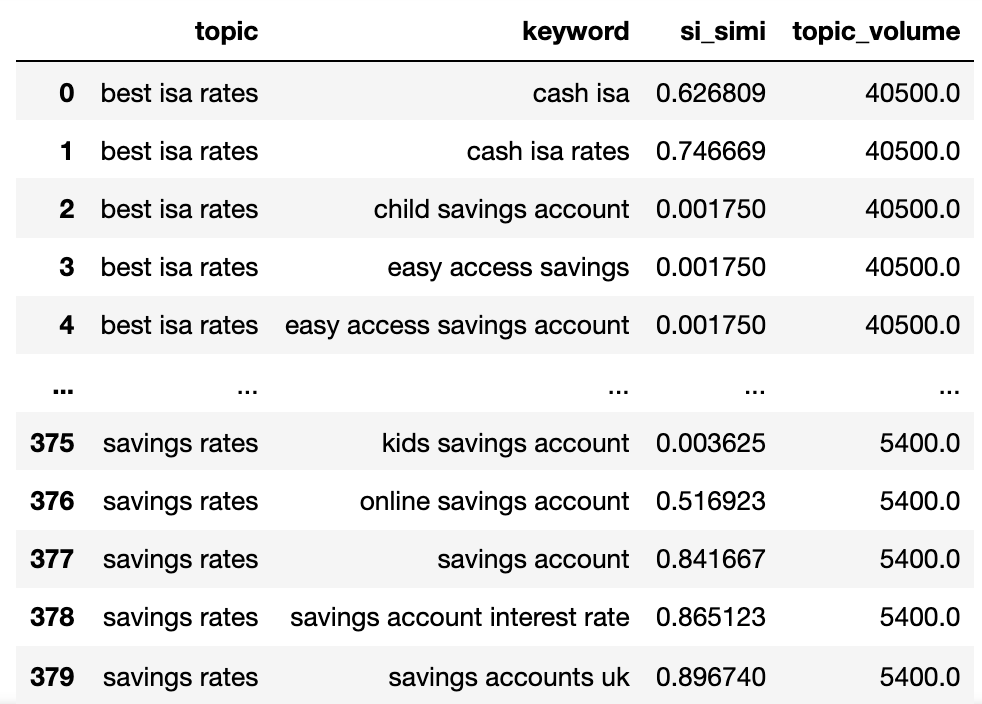
Observará que Keyword y Keyword_B han sido renombrados al tema y la palabra secreto, respectivamente.
Ahora vamos a iterar sobre las columnas en el entorno de datos utilizando la técnica Lambda.
La técnica Lambda es una forma válido de iterar sobre las filas en un entorno de datos de Pandas porque convierte las filas en una letanía en área de la función .itrows ().
Aquí va:
queries_in_df = list(set(matched_serps('keyword').to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for k, v in dicto.items():
if vala in v:
return k
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups(keyw) = (keyw)
sim_topic_groups(keyw) = (topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups(d_key).append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups(d_key).append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups(keyw).append(topc)
sim_topic_groups(keyw).append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups(topc).append(keyw)
sim_topic_groups(topc).append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups(keyw)) > len(sim_topic_groups(topc)):
sim_topic_groups(keyw).append(topc)
(sim_topic_groups(keyw).append(x) for x in sim_topic_groups.get(topc))
sim_topic_groups.pop(topc)
elif len(sim_topic_groups(keyw)) < len(sim_topic_groups(topc)):
sim_topic_groups(topc).append(keyw)
(sim_topic_groups(topc).append(x) for x in sim_topic_groups.get(keyw))
sim_topic_groups.pop(keyw)
elif len(sim_topic_groups(keyw)) == len(sim_topic_groups(topc)):
if sim_topic_groups(keyw) == topc and sim_topic_groups(topc) == keyw:
sim_topic_groups.pop(keyw)
elif si < simi_lim:
if (not dict_key(non_sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups,keyw)):
non_sim_topic_groups(keyw) = (keyw)
if (not dict_key(non_sim_topic_groups, topc)) and (not dict_key(sim_topic_groups, topc)) and (not dict_values(sim_topic_groups,topc)):
non_sim_topic_groups(topc) = (topc)
A continuación muestra un diccionario que contiene todas las palabras secreto agrupadas por la intención de búsqueda en grupos numerados:
{1: ('fixed rate isa',
'isa rates',
'isa interest rates',
'best isa rates',
'cash isa',
'cash isa rates'),
2: ('child savings account', 'kids savings account'),
3: ('savings account',
'savings account interest rate',
'savings rates',
'fixed rate savings',
'easy access savings',
'fixed rate bonds',
'online savings account',
'easy access savings account',
'savings accounts uk'),
4: ('isa account', 'isa', 'isa savings')}Peguemos eso en un entorno de datos:
topic_groups_lst = ()
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append((k, v))
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=('topic_group_no', 'keyword'))
topic_groups_dictdf
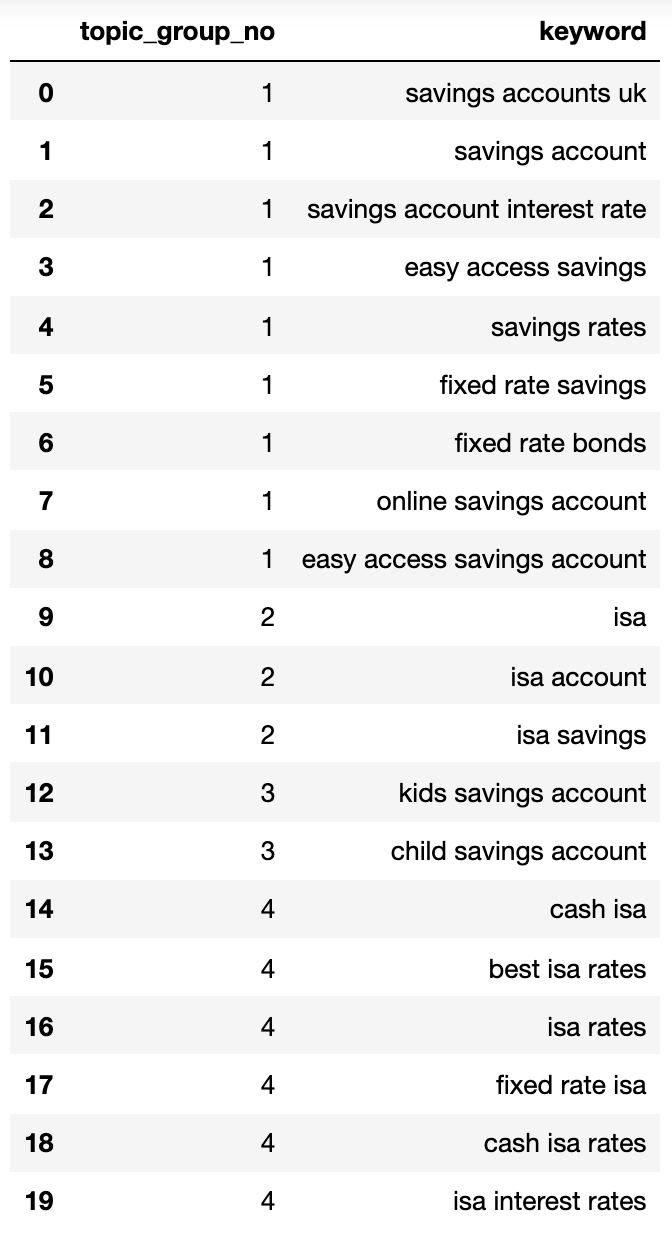 Imagen del autor, abril de 2025
Imagen del autor, abril de 2025Los grupos de intención de búsqueda anteriores muestran una buena tratamiento de las palabras secreto en el interior de ellas, poco que un hábil en SEO probablemente lograría.
Aunque solo usamos un pequeño conjunto de palabras secreto, el método obviamente puede escalarse a miles (si no más).
Activar las expectativas para mejorar su búsqueda
Por supuesto, lo preliminar podría tomarse más a fondo utilizando redes neuronales, procesando el contenido de clasificación para los grupos más precisos y los nombres de grupos de clúster, como ya lo hacen algunos de los productos comerciales.
Por ahora, con esta salida, puede:
- Incorpore esto en sus propios sistemas de tablero de SEO para hacer sus tendencias y Informes de SEO más significativo.
- Construir mejor campañas de búsqueda pagadas Al organizar sus cuentas de anuncios de Google por intención de búsqueda para un puntaje de longevo calidad.
- Fusionar URL redundantes de búsqueda de comercio electrónico apariencia.
- Instrumentar la taxonomía de un sitio de compras de acuerdo con la intención de búsqueda en área de un catálogo de productos pintoresco.
Estoy seguro de que hay más aplicaciones que no he mencionado: no dude en comentar sobre cualquiera importante que ya no haya mencionado.
En cualquier caso, su investigación de palabras secreto de SEO obtuvo un poco más de escalable, preciso y más rápido.
Descargar el código completo aquí para su propio uso.
Más capital:
Imagen destacada: Buch y Bee/Shutterstock