


Esto es un publicación de invitado – ¡el primero en mucho tiempo! El prólogo y el resumen los escribo yo, Simo, y el resto lo escribe mi estimado autor invitado.
¡Qué suerte tuve de haber sido contactado por Arben KqikuGerente de Datos y Advertising and marketing Digital de juntos. Arben es uno de nuestros muchos Hervir a fuego lento estudiantes, y ha caminado por el Consultar datos GA4 en Google BigQuery Por supuesto, aprendiendo mucho en el camino.
Quería compartir conmigo este maravilloso estudio de caso que escribió utilizando las lecciones aprendidas durante ese curso y su conocimiento previo de herramientas y lenguajes como RHojas de cálculo de Google y Google Information Studio.
En este artículo, Arben aborda la antigua cuestión de cómo medir una efectividad del weblog. Los datos se basan en un conjunto de datos de BigQuery generado a partir de este weblog, que está disponible para todos los que toman el curso de BigQuery a fuego lento.
X
El boletín a fuego lento
Suscríbete al Boletín a fuego lento para recibir las últimas noticias y contenido de Simo Ahava en su bandeja de entrada de correo electrónico.
Un análisis net del weblog de Simo Ahava
Recientemente terminé el Consultar datos GA4 en Google BigQuery curso, producido por Simo Ahava e impartido por Johan van de Werken. Como sugiere el nombre, aprenderá a realizar consultas. Google Analytics 4 datos mediante el uso Google BigQueryen este caso específicamente los datos del weblog GA4 de Simo Ahava.
Quería poner a prueba mis conocimientos recién adquiridos y es por eso que escribí este artículo.
¿Cómo medir la efectividad de un weblog?
Un weblog se compone de artículos, por lo que, lógicamente, debemos comparar estos artículos para comprender cuál funciona mejor. Sin embargo, ¿qué KPI deberíamos utilizar?
podríamos usar visitas a la página – Cuantas más páginas vistas genere un artículo, mejor. Esto ciertamente tiene sentido ya que las visitas a la página pueden interpretarse como un indicador de interés. Sin embargo, esta métrica tiene algunas limitaciones. Por ejemplo, la gente podría visitar un artículo y abandonarlo inmediatamente sin leerlo. Entonces, necesitamos una métrica que indique si alguien ha leído un artículo o no.
Podríamos utilizar el Google Analytics 4 Desplazarse evento para este propósito. GA4 registra un evento de desplazamiento cada vez que un usuario se desplaza a 90% de la longitud complete de una página. Puede Indique a GA4 que recopile automáticamente este evento. y otros desde la interfaz GA4.
Sin embargo, esta métrica también tiene sus limitaciones. Es decir, la extensión entre artículos varía mucho. Una página con sólo 300 palabras generará más eventos de desplazamiento que una página con 8000 palabras, simplemente porque es más fácil llegar al ultimate. Por lo tanto, necesitamos encontrar una manera de integrar la longitud de un artículo en la ecuación.
Una fórmula para medir el atractivo de un artículo
En primer lugar, podríamos utilizar eventos de desplazamiento y visitas a la página para calcular la tasa de conversión de desplazamiento utilizando la siguiente fórmula:
pergaminos / visitas a la página
Sin embargo, podríamos tener 2 páginas con la misma tasa de conversión de desplazamiento, una página con 10 vistas y la otra con 1000 vistas. Obviamente, una página con 1000 visitas es más valiosa, por lo que debemos perfeccionar nuestro enfoque.
Como se mencionó anteriormente, un pergamino es más valioso en una página con 8000 palabras que en una página con 300 palabras. Entonces, podríamos usar una fórmula que pondere el número de pergaminos por el número de palabras presentes en un artículo:
pergaminos * recuento_palabras
De esta forma, damos más peso a los artículos más extensos.
Ahora que la parte abstracta del artículo está terminada, pasemos a la parte jugosa, el código.
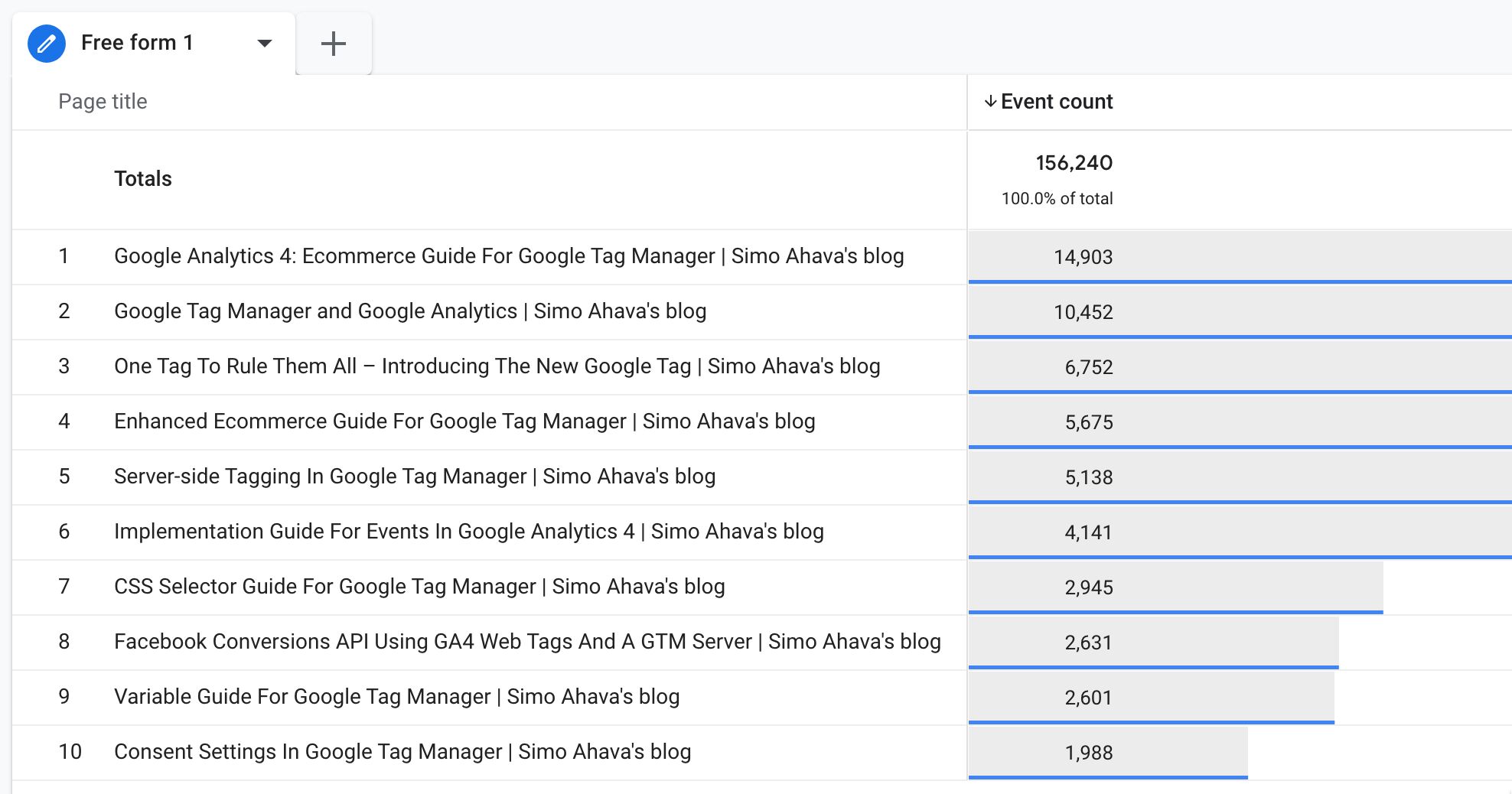
Puntuación de rendimiento de cada artículo con pergaminos y recuento de palabras.
En BigQuery, es bastante fácil extraer desplazamientos por página.
choose
(choose worth.string_value from unnest(event_params) the place key = 'page_location') as page_location,
countif(event_name = 'scroll') as scrolls
from
`dataset.desk.events_*`
the place
_table_suffix between '20220601' and '20220831'
group by
page_location
order by
page_views descMiremos más de cerca.
Primero, con el siguiente código, necesitamos extraer el page_location parámetro de evento. Para hacerlo, primero debemos desnudar los parámetros del evento y luego seleccione el page_location parámetro.
(choose worth.string_value from unnest(event_params) the place key = 'page_location') as page_locationLos eventos de desplazamiento son más fáciles de extraer: simplemente necesitamos decirle a BigQuery que cuente un evento cada vez que encuentre un evento de desplazamiento mientras analiza la tabla de origen.
countif(event_name = 'scroll') as scrollsFinalmente, necesitamos agrupar por page_locationporque queremos utilizar los desplazamientos por página en nuestra fórmula.
Para extraer el recuento de palabras por página, se requieren herramientas adicionales. Para ello, utilicé R y Google Sheets.
Lo primero que hice fue extraer las páginas que tenían al menos 100 páginas vistas entre el 1 de junio y el 31 de agosto, y pegué los resultados en esta hoja de Google.

Luego, usé R para calcular el recuento de palabras de cada página.
Sin embargo, encontré un obstáculo al recuperar las páginas HTML. Es decir, hubo un lote de información que no correspondía a palabras reales, como fragmentos de código JavaScript y estilos CSS. Por eso comparé cada palabra con un diccionario de inglés y solo conté palabras reales en inglés.
Estos son los pasos concretos que tomé en R:
- Cargar paquetes
- Recupere todas las URL de las páginas de la hoja de Google vinculada anteriormente
- Recuperar un diccionario de inglés de GitHub
- Para cada página:
4.1. Recuperar todas las palabras
4.2. limpia las palabras
4.3. Únete al diccionario de inglés
4.4. Vea si hay una coincidencia en el diccionario. Si lo hay, cuéntalo como 1 (TRUE)
4.5. Suma todas las palabras que coinciden en el diccionario. - Genere el resultado en la misma hoja de Google
Así es como se ve el resultado.
Y este es el código R que utilicé.
# Packages
library(tidyverse)
library(googlesheets4)
library(rvest)
# Retrieve knowledge from Google sheet
sheet_URL = 'https://docs.google.com/spreadsheets/d/1tkOnw41zj7lQLonV-bEjJFszY5jSlMylmn9ntQO2qcA/edit#gid=0'
sheet_id = gs4_get(sheet_URL)
page_data = range_read(sheet_id)
# Retrieve English dictionary
dict = learn.desk(file = url("https://github.com/dwyl/english-words/uncooked/grasp/words_alpha.txt"), col.names = "phrases") %>%
as_tibble() %>%
mutate(situation = TRUE)
# Learn knowledge from net pages and depend phrases per web page
words_per_page = page_data %>%
mutate(phrases = map(Web page, ~return_words(web_page = .x))) %>%
mutate(phrases = phrases %>% unlist())
# Output knowledge to Google sheets
sheet_write(words_per_page, sheet = 'output', ss = sheet_id)
# Capabilities
return_words = perform(web_page).A continuación, en Google Sheets, creé un case...when declaración para cada página para crear una columna para el recuento de palabras en BigQuery.

Luego copié todos estos case...when declaraciones y las pegué nuevamente en BigQuery. Para evitar mostrar una consulta con 358 case...when declaraciones, sólo mostraré algunas de ellas aquí.
with prep as (
choose
(choose worth.string_value from unnest(event_params) the place key = 'page_location') as page_location,
countif(event_name = 'scroll') as scrolls
from
`simoahava-com.analytics_206575074.events_*`
the place
_table_suffix between '20220601' and '20220831'
group by
page_location
order by
page_views desc),
prep_words as (
choose
*,
case
when page_location = 'https://www.simoahava.com/analytics/google-analytics-4-ecommerce-guide-google-tag-manager/' then 5865
when page_location = 'https://www.simoahava.com/' then 521
when page_location = 'https://www.simoahava.com/analytics/one-tag-rule-them-all-introducing-google-tag/' then 1365
else null finish as words_per_article
from
prep)
choose
*,
scrolls * words_per_article as performance_score
from
prep_words
order by
performance_score descCárgalo todo en Google Information Studio
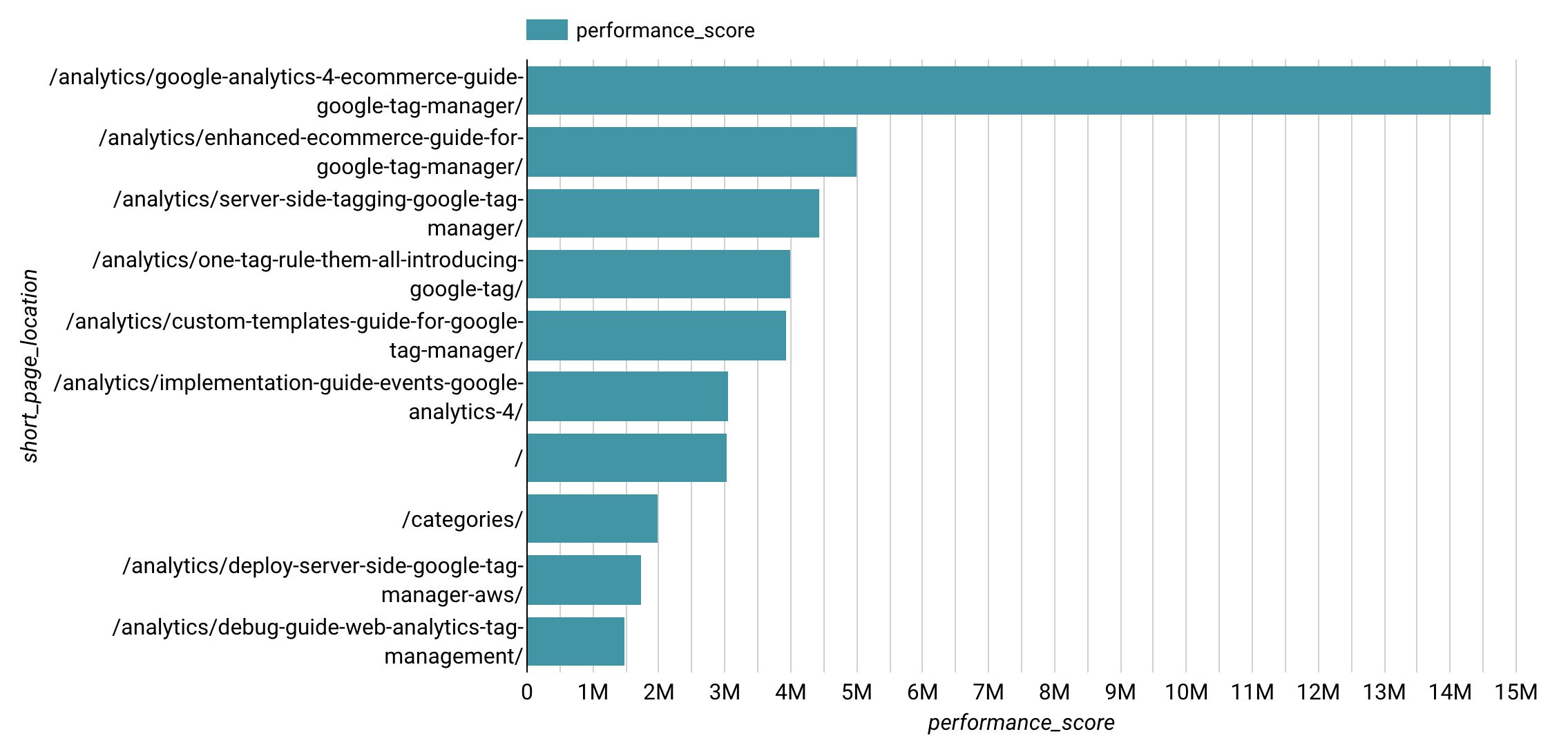
Con Google Information Studio, creé este gráfico de barras horizontales que muestra la puntuación de rendimiento por página.
Podemos ver claramente que el artículo Google Analytics 4: Guía de comercio electrónico para Google Tag Supervisor domina los resultados.
Puntuación de rendimiento por página y fuente/medio
Además de saber qué artículos tienen la mejor puntuación de rendimiento, sería interesante ver cómo se comparan cuando se segmentan por fuente / medio. Puede ser que ciertas combinaciones de fuente/medio puedan atraer más usuarios interesados.
with prep as (
choose
concat(traffic_source.supply, " / ", traffic_source.medium) as source_medium,
(choose worth.string_value from unnest(event_params) the place key = 'page_location') as page_location,
countif(event_name = 'scroll') as scrolls
from
`simoahava-com.analytics_206575074.events_*`
the place
_table_suffix between '20220601' and '20220831'
group by
source_medium,
page_location
order by
scrolls desc),
prep_words as (
choose
*,
case
when page_location = 'https://www.simoahava.com/analytics/google-analytics-4-ecommerce-guide-google-tag-manager/' then 5865
when page_location = 'https://www.simoahava.com/' then 521
when page_location = 'https://www.simoahava.com/analytics/one-tag-rule-them-all-introducing-google-tag/' then 1365
else null finish as words_per_article
from
prep)
choose
source_medium,
page_location,
sum(page_views) as page_views,
sum(scrolls) as scrolls,
sum(words_per_article) as words_per_article,
sum(scrolls * sum(words_per_article) as performance_score
from
prep_words
group by
source_medium,
page_location
having
words_per_article is not null
and scrolls > 100
order by
page_views descNota de Simo: esta consulta utiliza el
traffic_source.*dimensiones para fuente/medio. Estos son en realidad los primera adquisición detalles de la campaña en lugar de los metadatos de la campaña con ámbito de sesión de los que esta consulta se beneficiaría en mayor medida. Desafortunadamente, en el momento de escribir este artículo, datos de ámbito de sesión como este no están disponibles en la exportación de BigQuery, por lo que usartraffic_source.*es un proxy bastante decente.
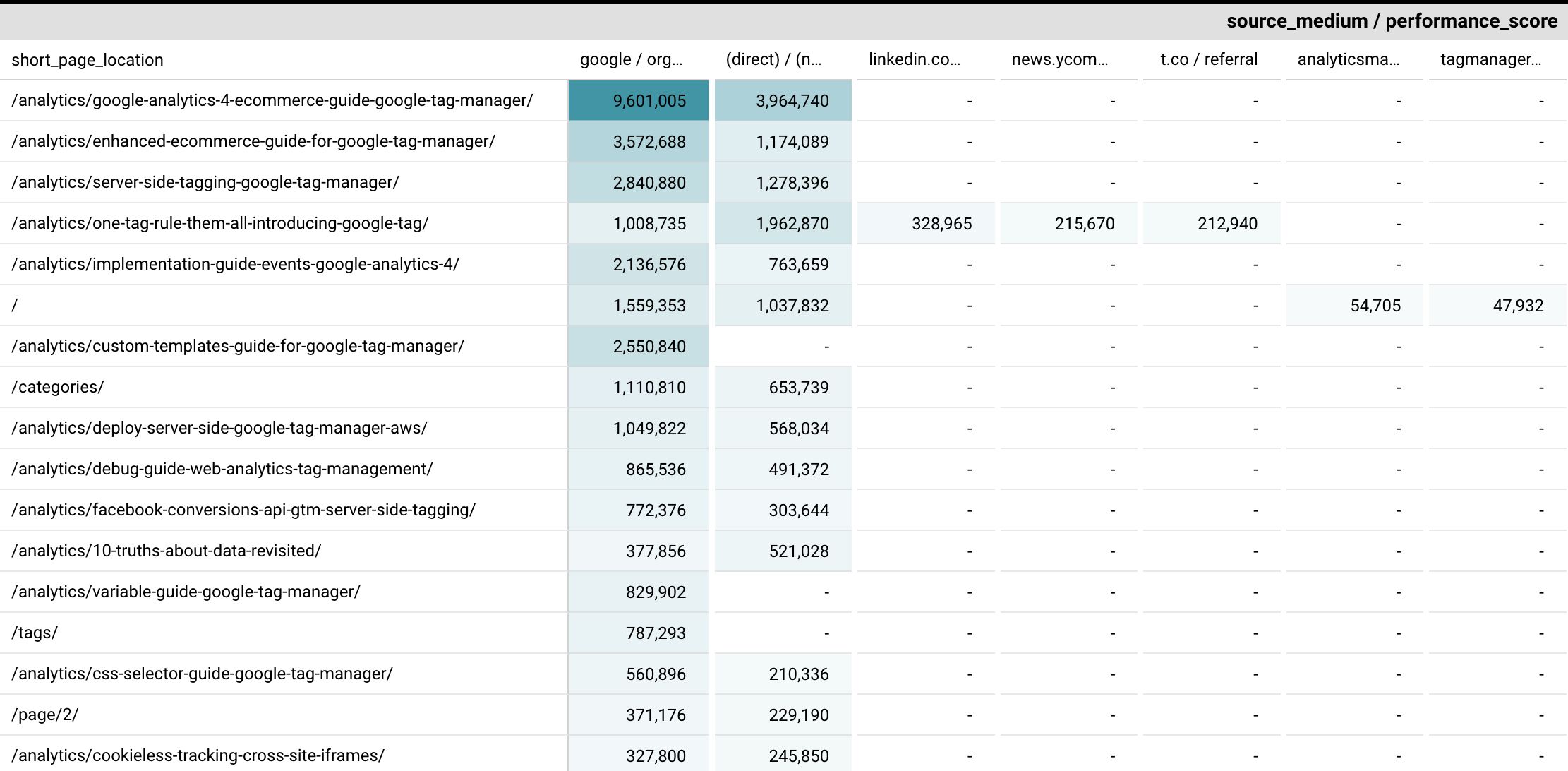
Cuando divides los datos en dos dimensiones, a veces resulta útil visualizarlos con un mapa de calor.
En este caso, podemos ver que el fuente / medio con el puntaje de desempeño más alto es google / natural.
Sólo seleccioné combinaciones con al menos 100 pergaminos. Es por eso que el lado derecho del mapa de calor está prácticamente vacío.
Sin embargo, es interesante observar que el cuarto artículo de la lista, Una etiqueta para gobernarlos a todos: presentamos la nueva etiqueta de Googletambién tiene una puntuación de rendimiento para otras fuentes.
Esto nos cube que el artículo en cuestión tiene una penetración más amplia en cuanto a canales de adquisición.
Atribuir una puntuación de rendimiento a cada usuario
Para asociar una puntuación de rendimiento a cada usuario, usaremos el campo GA4 user_pseudo_idque almacena el identificador de cliente que GA4 atribuye a cada instancia del navegador. Aunque no refleja necesariamente el número actual de gente que visitan el sitio, nuevamente es un proxy lo suficientemente decente como para brindarnos algunos resultados útiles.
Lo primero que debe hacer es crear la consulta que alinee el user_pseudo_id Juntos con page_locationel número de eventos de desplazamiento y el recuento de palabras de cada página.
with prep as (
choose
user_pseudo_id,
(choose worth.int_value from unnest(event_params) the place key = 'ga_session_id') as session_id,
(choose worth.string_value from unnest(event_params) the place key = 'page_location') as page_location,
countif(event_name = 'scroll') as scrolls,
from
`simoahava-com.analytics_206575074.events_*`
the place
_table_suffix between '20220601' and '20220831'
group by
user_pseudo_id,
session_id,
page_location
order by
scrolls desc)
choose
user_pseudo_id,
session_id,
page_location,
case
when page_location = 'https://www.simoahava.com/analytics/google-analytics-4-ecommerce-guide-google-tag-manager/' then 5865
when page_location = 'https://www.simoahava.com/' then 521
when page_location = 'https://www.simoahava.com/analytics/one-tag-rule-them-all-introducing-google-tag/' then 1365
else null finish as words_per_page,
scrolls
from
prepAsí es como se ven los resultados de la consulta.
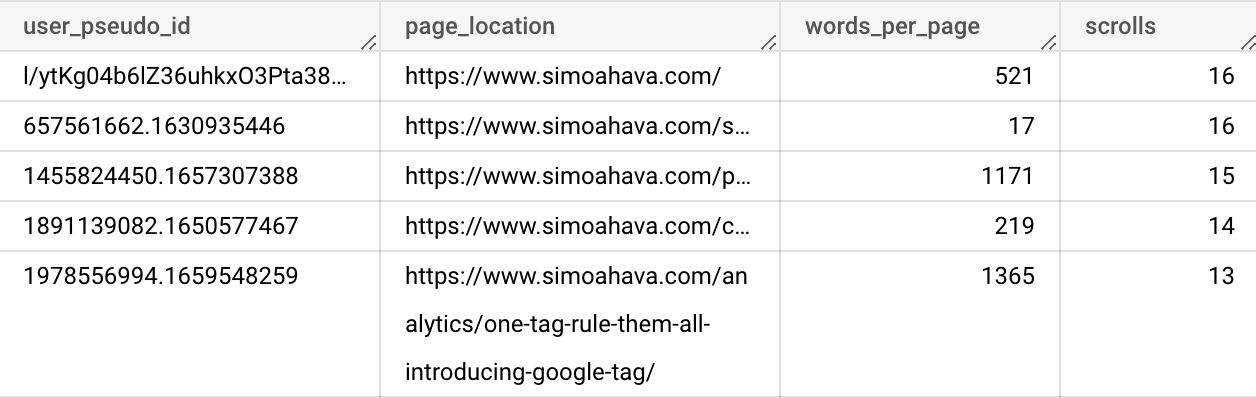
Ahora puedo crear una consulta para analizar la tabla de resultados que se muestra arriba y obtener la puntuación de rendimiento por usuario.
with prep as (
choose
user_pseudo_id,
sum(words_per_page) as words_per_page,
sum(scrolls) as scrolls
from
`dataset.result_table`
group by
user_pseudo_id
having
words_per_page is not null)
choose
user_pseudo_id,
scrolls,
words_per_page,
scrolls * words_per_page as performance_score
from
prep
order by
performance_score descAquí está el resultado.
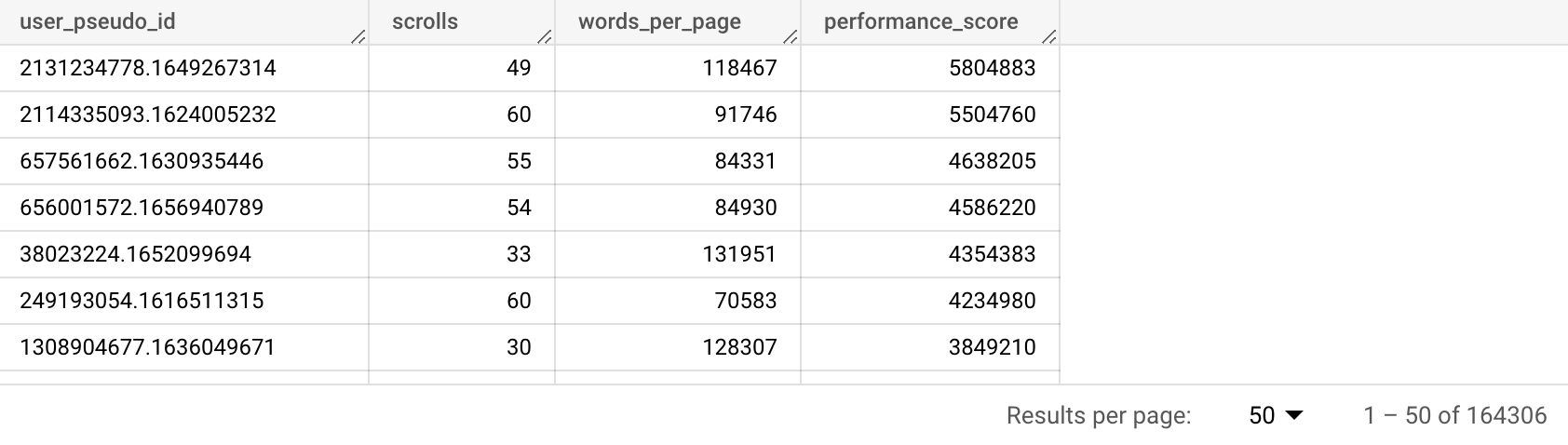
En complete, hemos podido atribuir una puntuación de rendimiento a 164.306 usuarios. Podríamos utilizar esta información para crear audiencias de remarketing al importando los datos en GA4. Alternativamente, podríamos agregar esta información a nuestro CRM y usarla como sistema de puntuación de clientes potenciales para potenciar nuestras campañas de correo electrónico.
Resumen (por Simo)
¡Gracias Arben!
La efectividad del contenido es brutalmente difícil de medir. He intentóy intentóy intentó He visitado este tema una y otra vez en la historia de este weblog, y nunca he descubierto qué fórmula funcionaría mejor.
No estoy diciendo que Arben haya resuelto el rompecabezas, pero sí plantea un punto importante sobre cómo profundizar más de lo que nos ofrecen las métricas predeterminadas.
En última instancia, el compromiso es algo lo suficientemente efímero como para resistir ser encasillado en una fórmula common. Siempre me ha disgustado cuando las plataformas de análisis intentan insertar significado en las métricas clínicas nombrándolas algo como “Tasa de participación” o “Tasa de rebote”. Son sólo métricas. Si describen el compromiso es una discusión completamente diferente.
Espero que te haya inspirado la exploración de Arben de las diferentes herramientas disponibles en el arsenal del analista. Puede llegar lejos solo con Google BigQuery, pero usar R y Google Sheets para crear el conjunto de datos base puede resultar extremadamente valioso a largo plazo.
Por favor consulte Perfil de Arben en LinkedInconéctate con él y comparte tus pensamientos sobre su trabajo con él.