


Última actualización: 18 de octubre de 2021. Peview ahora funciona con el contenedor proxy incluso si se anula el ID del contenedor.
Mientras etiquetado del lado del servidor ya tiene un maravilloso Cliente incorporado para proxy del contenedor de Google Tag Supervisor a través de su propio dominio propio, no es perfecto.
Los principales problemas son que no le permite delimitar el acceso por origen, por lo que las solicitudes de ID de contenedor incluidos en la lista permitida se pueden enviar desde cualquier lugar, y que no le permite elegir libremente la ruta a través de la cual se enviará el ID de contenedor. está cargado.
Para abordar estos problemas, me complace revelar que he escrito un nueva plantilla de cliente para contenedores de servidor, llamados Cargador GTM.
Las principales características de esta plantilla son:
- Elija libremente a qué ruta de solicitud responde el Cliente. Puedes mantener el valor predeterminado
/gtm.jso puedes optar por algo más imaginativo, como/green-dragons. - Cargue siempre un contenedor con un ID específico, independientemente de lo que haya (si es que hay algo) en el
?id=parámetro de la solicitud. - Solo permita solicitudes de orígenes específicos.
¡Siga leyendo para obtener más información!
X
El boletín a fuego lento
Suscríbete al Boletín a fuego lento para recibir las últimas noticias y contenido de Simo Ahava en su bandeja de entrada de correo electrónico.
Obtener la plantilla
como el Galería de plantillas comunitarias aún no distribuye plantillas de Cliente, deberá importar manualmente el archivo de plantilla.
Primero, busca el crudo. template.tpl archivo del repositorio de GitHub siguiendo este enlace y guardar la página como template.tpl en tu computadora.
Entonces, en tu Servidor contenedor, vaya a Plantillas y haga clic Nuevo en el cuadro de Plantillas de cliente.
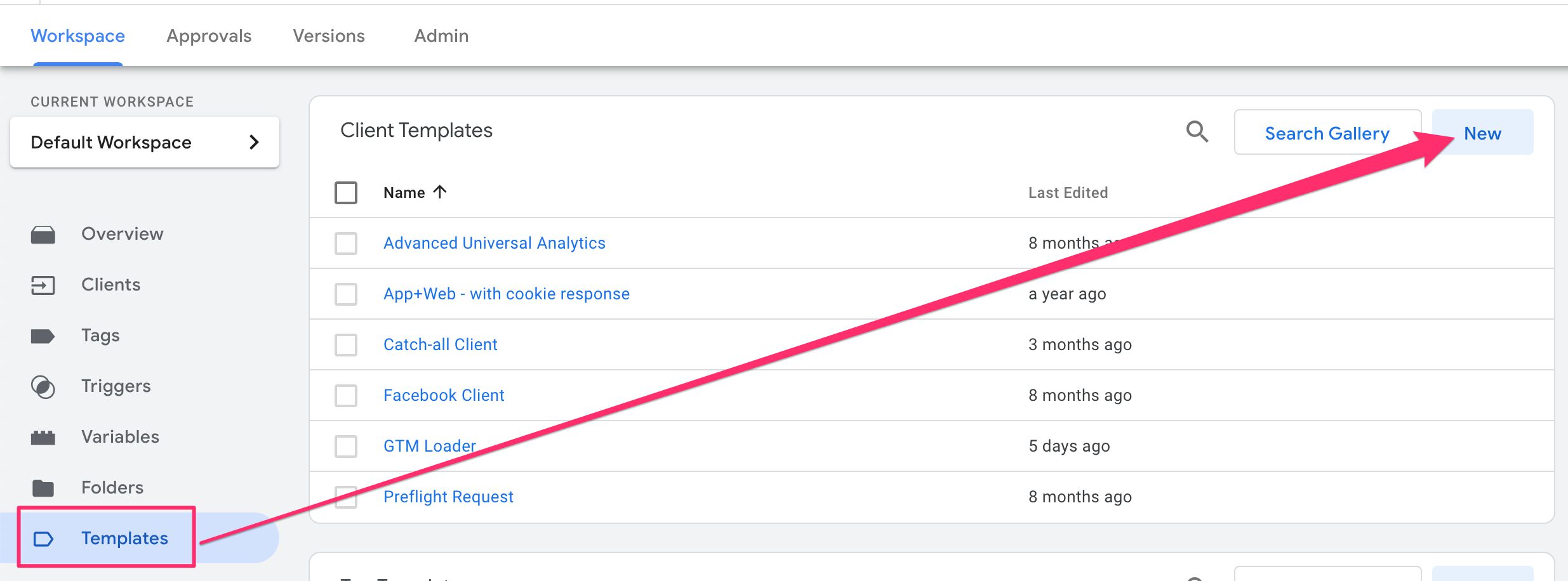
En el menú adicional en la esquina superior derecha de la pantalla, elija Importar.
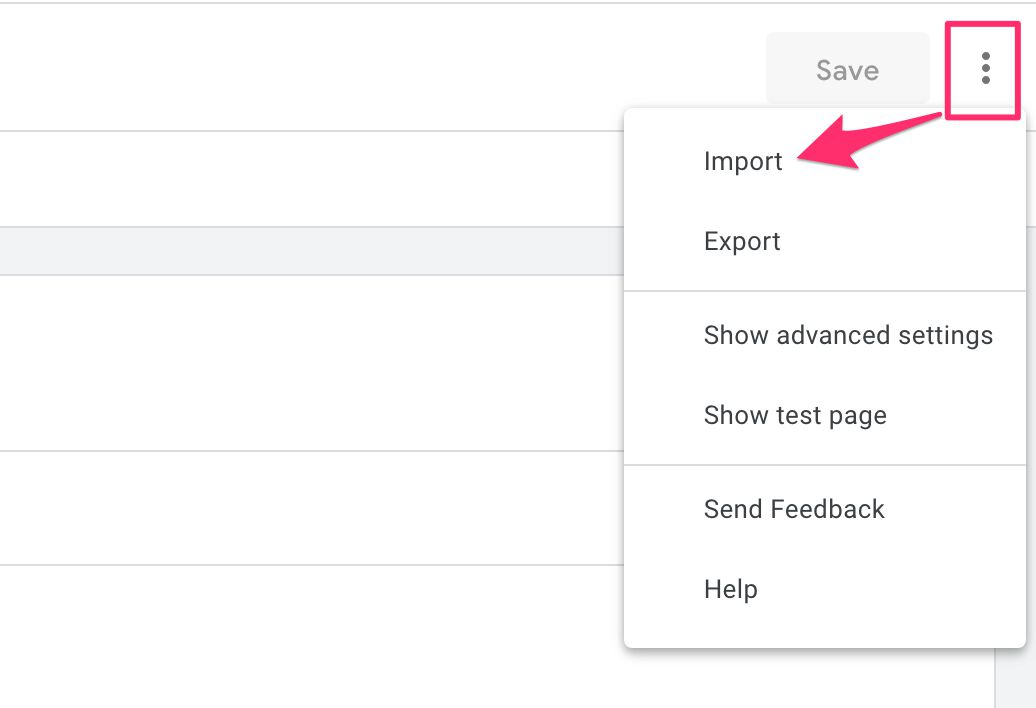
Localice el template.tpl archivo de su contenedor, espere a que el editor se actualice con la plantilla de GTM Loader y luego haga clic en Ahorrar para guardar la plantilla.
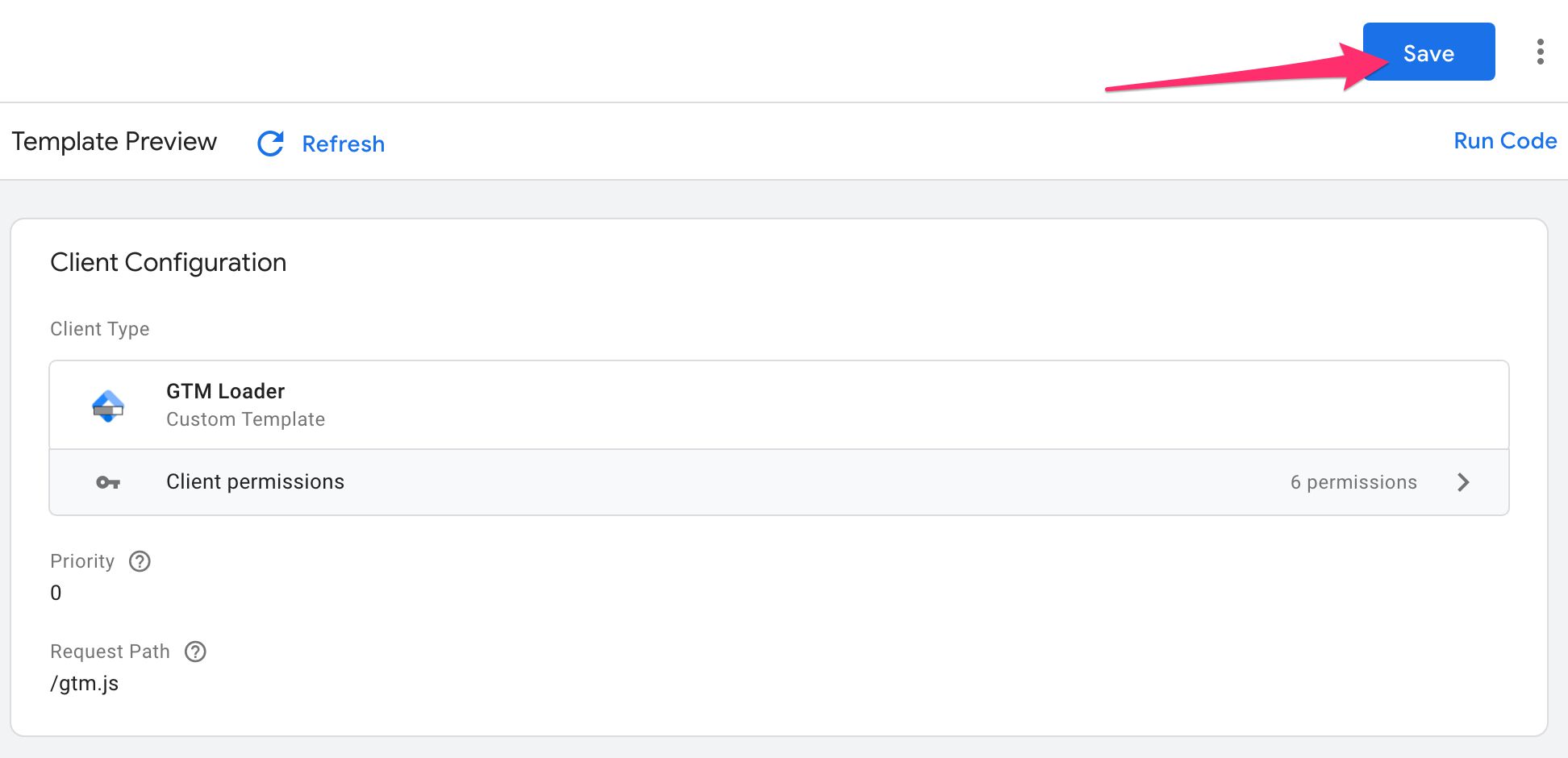
Crear un nuevo Cliente
Dirígete a Clientela en su contenedor y haga clic Nuevo para crear un nuevo Cliente.
De la lista de Clientes disponibles, elija el Cargador GTM Cliente.
¡Deberías estar listo ahora para personalizar el nuevo Cliente!
Configurar el cliente
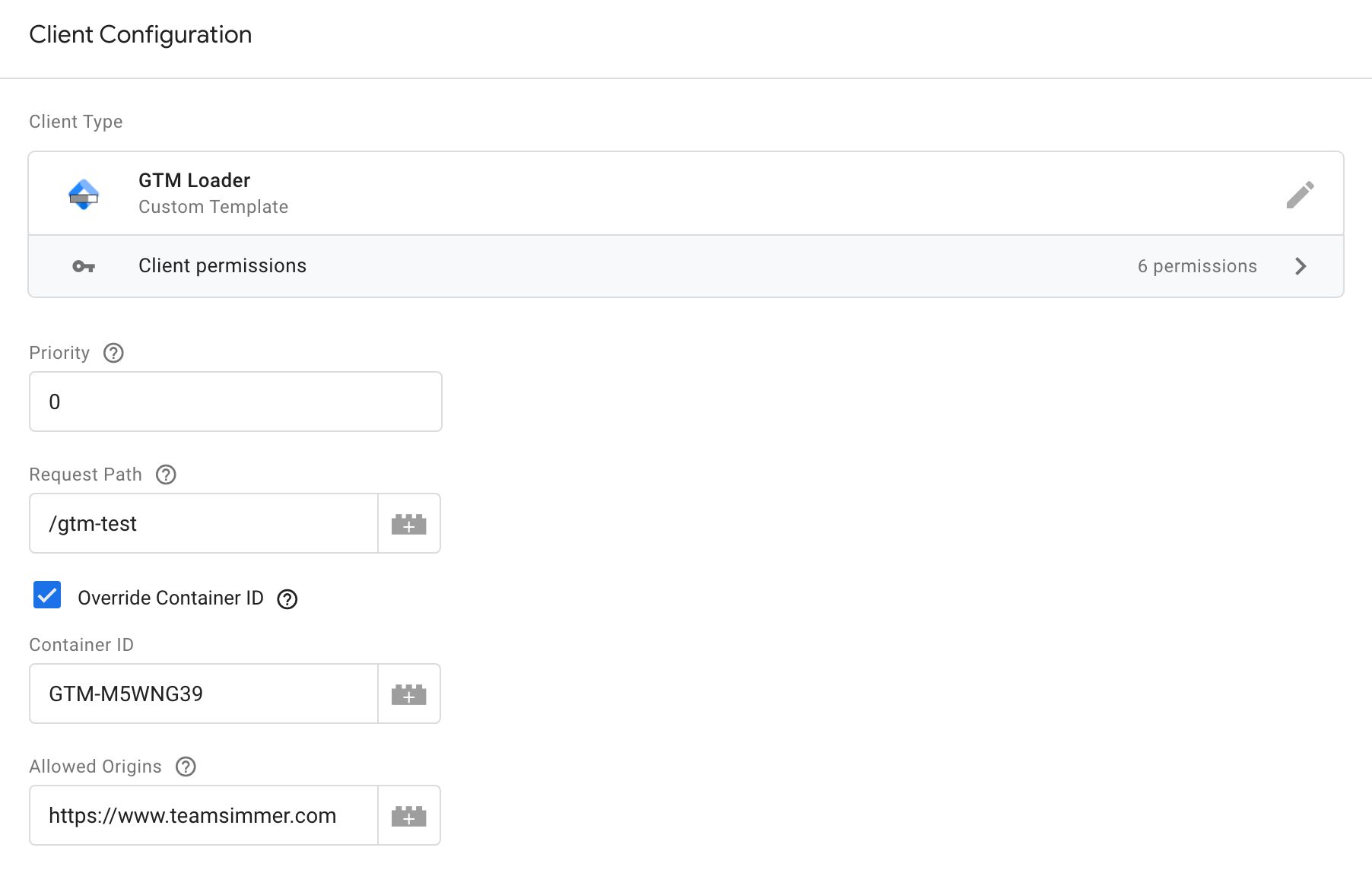
Así es como se ve el Cliente con todos los campos disponibles en pantalla:
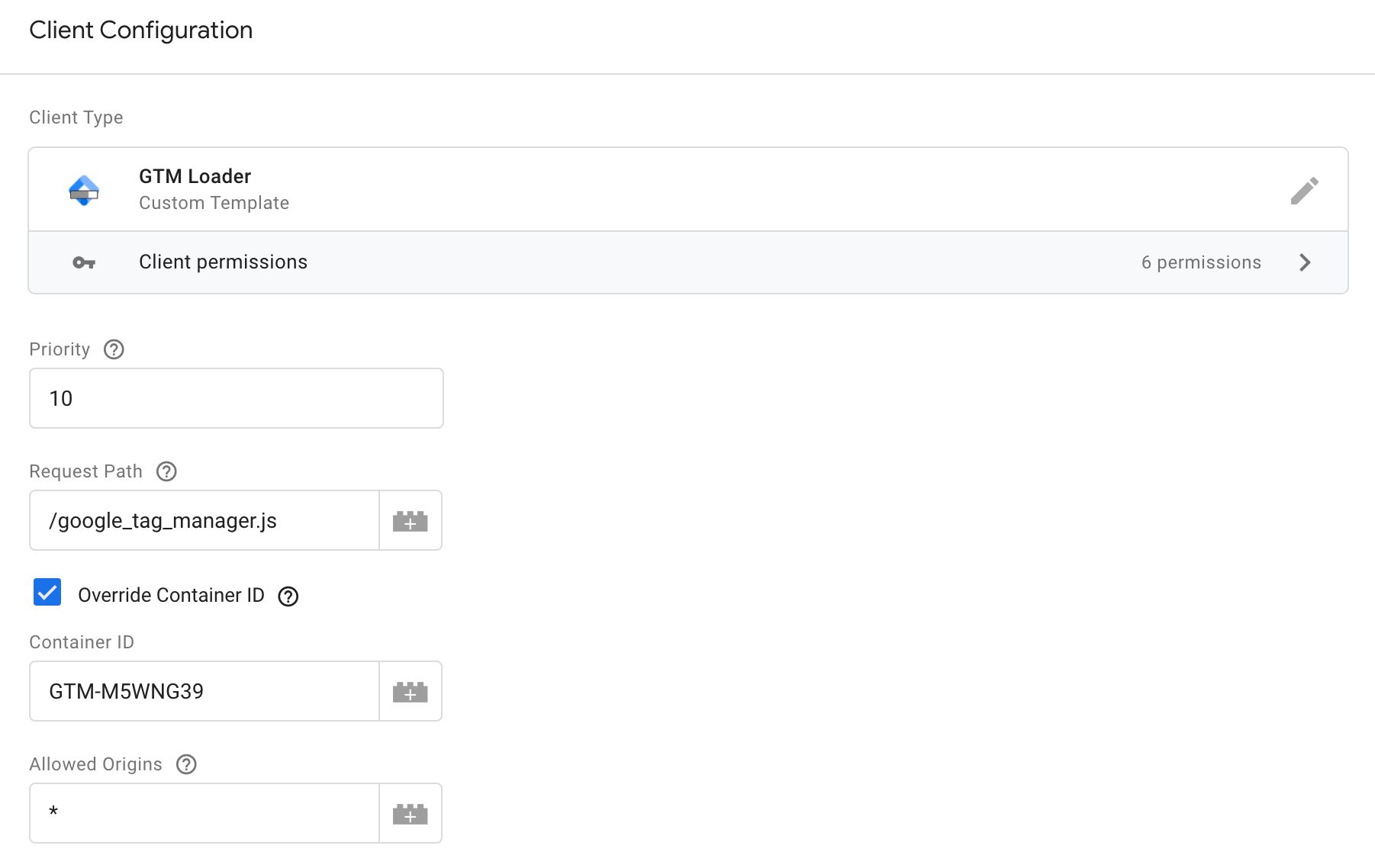
Ruta de solicitud
Establezca esto en una ruta (incluya la barra diagonal inicial). También puedes mantener el valor predeterminado. /gtm.js si lo desea.
El Cliente estará escuchando las solicitudes a esta ruta, y si un coincidencia exacta se realiza, el Cliente reclamará la solicitud y obrará sus maravillas.
Por ejemplo, si establece la ruta en /google_tag_manager.js como en la captura de pantalla anterior, luego una solicitud para https://
Recuerda que es coincidencia exacta! La solicitud debe tener una ruta que coincida exactamente con la configuración que configure en este Cliente.
Anular ID de contenedor
¡Importante! Si anula el ID del contenedor, Avance Los contenedores se cargarán, pero el navegador debe realizar una solicitud adicional para
www.googletagmanager.com. Entonces, si su sitio tiene una Política de seguridad de contenido,https://www.googletagmanager.comAún se debe agregarle para que el modo Vista previa funcione correctamente.
Si marca esta configuración, podrá agregar una ID de contenedor válida de Google Tag Supervisor al campo respectivo.
Esta configuración significa que independientemente de lo que haya en el ?id= parámetrose devolverá un contenedor con el ID configurado.
Cuando hayas marcado esta configuración, podrás soltar el ?id= parámetro de la solicitud por completo, ya que el contenedor con el ID configurado se cargará en todos los casos.
Orígenes permitidos
En este campo, puede agregar una lista separada por comas de orígenes de las cuales sólo se respetarán las solicitudes.
Por ejemplo, si agrega https://www.teamsimmer.com,https://www.simoahava.com al campo, entonces solo las solicitudes de esos dos orígenes podrán recuperar el contenedor.
Recuerde que el origen es el esquema (http o https) más :// más nombre de host más puerto. Básicamente todo hasta la ruta de solicitud.
También puedes agregar * a este campo, en cuyo caso el Cliente reclamará la solicitud independientemente de su origen.
Si necesita proporcionar manualmente el origen (por ejemplo, cuando trabaja con un recurso integrado o cuando realiza pruebas), puede agregar &origin=<origin> a la URL de solicitud. Por ejemplo, para cargar el contenedor incluso cuando no estoy en https://www.simoahava.com y lo configuré en el campo Orígenes permitidos, puedo buscar esto:
https://
Cómo funciona
Un Cliente creado con la plantilla escucha las solicitudes que se envían a la ruta de solicitud definida en la configuración del Cliente.
Validar la solicitud
Cuando se recibe una solicitud como esa, el Cliente realiza dos comprobaciones:
- Es el Anular ID de contenedor configuración marcada y se ha configurado un ID de contenedor GTM válido, O hay un ID de contenedor GTM válido como valor del
idparámetro de consulta en la solicitud? - ¿Es el valor de Orígenes permitidos el comodín (
*) O la solicitud proviene de un origen permitido O tiene un origen permitido como el valor de laoriginparámetro de consulta en la solicitud?
// If the incoming request matches the request configured within the Shopper
if (requestPath === information.requestPath) {
// If the request is for a sound GTM container ID
if (!containerId.match('^GTM-.+$')) return;
// If the request comes from a sound origin
if (!validateOrigin()) return;
...
}
Si ambos deciden truese reclama la solicitud.
Obtener el contenedor de vista previa
Si la solicitud es para un avance contenedor, lo que significa que tiene el gtm_debug, gtm_authy gtm_preview parámetros de consulta, el Cliente actúa como un proxy transparente.
Simplemente reenvía la solicitud a los servidores GTM con todos los encabezados y parámetros intactos y devuelve el resultado a la fuente de la solicitud.
const fetchPreviewContainer = () => {
sendHttpGet(
httpEndpoint +
'&id=' + containerId +
'>m_auth=' + gtm_auth +
'>m_debug=' + gtm_debug +
'>m_preview=' + gtm_preview,
(statusCode, headers, physique) => {
sendResponse(physique, headers, statusCode);
}, {timeout: 1500}
);
};
Es importante destacar que cuando se recupera un contenedor de vista previa, el resultado no está en caché. Esto es important para que la vista previa sea útil, ya que de lo contrario el usuario tendría que esperar a que caduque el caché antes de que el contenedor de vista previa actualizado esté disponible.
Obtener el contenedor en vivo
Cuando un vivir Se recupera el contenedor, por otro lado, el proceso cambia bastante.
La plantilla utiliza templateDataStoragecual es una API diseñado para conservar información entre solicitudes en el contenedor del servidor.
Cuando llega una solicitud para el contenedor en vivo, el Cliente verifica si ya existe una versión en caché de la biblioteca. y si el recurso se almacenó en caché menos de Hace 7,5 minutos. En este caso, la biblioteca almacenada en caché (y cualquier encabezado almacenado en caché) se devuelve al origen de la solicitud.
De esta manera el Cliente ahorra recursos al ya no tener que buscar el recurso de los servidores de Google.
¿Por qué una duración de caché de 7,5 minutos? Bueno eso es medio del tiempo de caché del navegador para la propia biblioteca GTM (15 minutos). De esta manera, la caché del navegador todavía tiene la última palabra sobre cuánto tiempo almacenar en caché el recurso, pero a diferencia de la caché del navegador, todos los usuarios Benefíciese del caché del lado del servidor incluso si el usuario nunca antes ha descargado el recurso.
Si el recurso no está almacenado en caché o si el caché ha caducado, el contenedor se recupera de los servidores de Google.
const fetchLiveContainer = () => {
const now = getTimestampMillis();
// Set timeout to 7.5 minutes
const storageTimeout = now - cacheMaxTimeInMs;
// If the cache has expired fetch library from Google servers and write response to cache
if (!templateDataStorage.getItemCopy(storedJs) ||
templateDataStorage.getItemCopy(storedTimeout) < storageTimeout) {
sendHttpGet(
httpEndpoint + '&id=' + containerId,
(statusCode, headers, physique) => {
if (statusCode === 200) {
templateDataStorage.setItemCopy(storedJs, physique);
templateDataStorage.setItemCopy(storedHeaders, headers);
templateDataStorage.setItemCopy(storedTimeout, now);
}
sendResponse(physique, headers, statusCode);
}, {timeout: 1500}
);
// In any other case, pull the merchandise from cache and don't make a request to Google servers
} else {
sendResponse(
templateDataStorage.getItemCopy(storedJs),
templateDataStorage.getItemCopy(storedHeaders),
200
);
}
};
Entonces templateDataStorage funciona aquí como una capa adicional de almacenamiento en caché, lo que scale back la latencia de respuesta del servidor y los costos de salida de la purple.
Resumen
¿Por qué crear una plantilla como esta cuando el cliente contenedor net incorporado funciona bien?
Los cínicos podrían decir que esta es una forma mejorada de eludir los bloqueadores de publicidad. ¡Y tendrían razón! Este hace facilitar la elusión de los bloqueadores de anuncios, ya que sus heurísticas se dirigen no sólo a los googletagmanager.com dominio sino también el gtm.js archivo y el GTM-... ID del contenedor.
Sin embargo, diseñé la plantilla para introducir flexibilidad adicional al mover Google Tag Supervisor a un contexto propio. Ser capaz de optimizar las rutas de solicitud y los parámetros de consulta parece una mejora obvia. El templateDataStorage La configuración agrega una capa adicional de optimización de costos.
Pero también está el problema de que tal vez los bloqueadores de anuncios dirigidos a Google Tag Supervisor estén tirando al bebé con el agua del baño. GTM en sí no es una herramienta de seguimiento y muchos la utilizan para fines completamente ajenos al seguimiento o la recopilación de datos.
Dicho esto, si hoy tuviera que diseñar un bloqueador de publicidad, probablemente también bloquearía GTM, ya que es más que possible que el agua del baño esté tan sucia que deba desecharse sin importar el daño colateral que trigger.
Así que es difícil lograr un equilibrio. Las únicas cosas que puedo recomendar son estas:
- Debería abordar el etiquetado del lado del servidor con mejores intenciones en el corazón.
- Haz tu mejor esfuerzo para mejorar en lugar de erosionar transparencia.
- Ser honesto y respetuoso a los visitantes de su sitio.
- Asegúrese de que estos mecanismos estén documentado en algún lugar para que si alguien auditara los flujos de datos en el sitio y el servidor, sus etiquetas no obstruyeran este importante trabajo.
De esta manera todos pasaremos un buen rato con el etiquetado del lado del servidor.